摘要
第一部分 引言
1)思科网络报告中显示,网络流量中东西向流量占比越来越大,其中数据中心设备之间的流量占71%,而数据中心之间的流量占14%。这样的增长趋势,说明东西向流量涉及到的光链路将会是一个庞大而快速增长的市场。该市场预计从2018年的$3B 增长到 2024 年的 $7B 以上。
2)随着带宽需求的增加,交换机及光模块在单位容量成本、带宽密度及能效方面也保持同步发展。从2010年至今,ASIC和光模块的容量都增加了40倍,ASIC从0.64Tb/到25.6Tb/s,光模块从10Gb/s到400Gb/s。
3)当前,800Gb/s可插拔光模块并未商用,采用8×100Gb/s Serdes技术实现时,电信号在信号完整性上遇到了巨大的挑战,导致Serdes功耗增加。因此,在整个光链路上的功耗增长迅速,大有超过交换芯片功耗的趋势。另外,功耗的增长,也约束了单台(1RU)交换机可部署的总容量。
4)单位容量成本也是一个重要问题。光模块的成本很大一部分在于组件和封装,和ASIC芯片不一样,不会因为半导体工艺技术提升而同步提升容量。因此,数据中心交换机在光模块上的投入成本也逐渐超过交换机本身。
5)带宽密度增长滞后:为了散热以及容纳数量更好的可插拔光模块,交换机高度增加一倍。下一步的发展,需要更高的通道速率、更多的通道数。
以上这些趋势,使得我们对光模块内部组件有更高的集成度及制造自动化的需求,进一步产生了对硅光技术的需求。进一步,交换机ASIC和光引擎的异构集成被认为是在解决集成密度、经济效益以及能效的好方法。
本文主要讨论了影响可插拔光模块转到共封装(CPO)技术的影响因素。尽管CPO还存在一些技术上的挑战,但采用CPO的主要障碍不是技术问题,而是如何克服整个行业对可插拔光模块使用的惯性。要推动该技术尽快落地,必须把CPO的显著优势讨论清楚,尤其是在能效 (pJ/bit) 和资本支出 ($/Gb/s) 方面实现显著收益(例如,50% 或更多),使得用户在总拥有成本TCO上获得收益。
数据中心光模块路标与交换机的路标密不可分。商用芯片的兴起极大地撼动了过去主要基于专有硬件和软件的交换机市场。当前,很多网络设备基于第三方芯片供应商设计和销售的 ASIC芯片进行设计。商用芯片现在占以太网数据中心交换机的 56% 以上。
这催生了网络设备白盒供应商和 ODM(原始设计制造商),他们根据自己或客户的设计构建基于商业芯片的网络设备。这一特点也进一步推动了可编程性的发展,例如 OpenFlow和 P4 、更广泛的软件定义网络 (SDN) 运动和开源SONiC、FBOSS、ONOS等网络操作系统。
以上趋势创造了一个更加开放的生态系统,其中网络运营商有更广泛的选择来根据其功能和成本要求定制他们的网络。他们甚至可以设计自己的网络硬件。
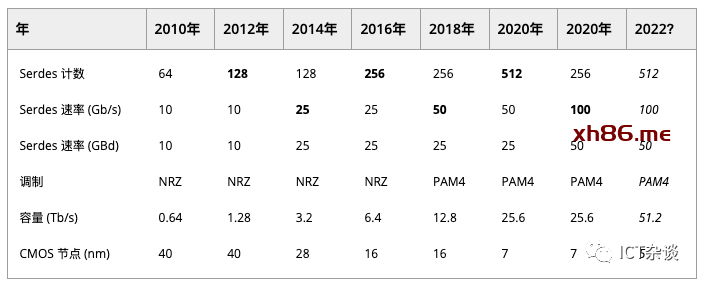
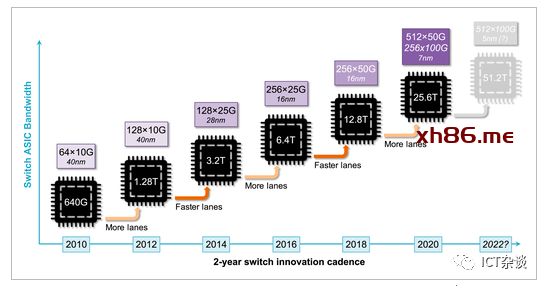
以太网交换机 ASIC 的发展有一个显著的特点:交替增加 Serdes 通道数量和通道速率,容量大约每 2 年翻一番。
表 1 交换机ASIC演进
图1 交换机ASIC 演进
图1还显示了 Serdes 波特率和调制类型。12.8 Tb/s第一个采用PAM4信令而不是传统的NRZ信令的,用较低的信噪比换取较高的比特波特率。
交换机的发展将继续在电接口、带宽方面推动光学技术的发展。当交换机、光模块的电口、光口都使用相同的速率和模式时,就可以满足总体最优。然而,在过渡阶段,采用Gearbox进行转换是有意义,这个阶段就是采用成熟的技术、成熟组件保护现有投资。
为了进一步提高容量,下一代交换机 ASIC 将采用 56 GBd PAM4 Serdes。在总容量增加到 51.2 Tb/s 之前,我们可能会看到第二代 25.6 Tb/s 芯片,将 Serdes 数量减半 (256 × 100 Gb/s) 并调整电通道和光通道速率。
每通道 100 Gb/s serdes 的能耗非常重要:在 51.2 Tb/s 时,每增加 1 pJ/bit 就会为芯片增加 51.2 W 的功率。最近的研究显示,采用10 nm FinFET CMOS技术下, 112 Gb/s 传输和接收电路能耗分别为 2 pJ/bit 和 4 pJ/bit,还不包括 DSP。因此,如果我们假设一共至少为6 pJ/bit,那么Serdes 功耗将超过 300 W。Serdes 占芯片功耗的典型比例为 30%,整个 ASIC 可能会超过 1 kW。
在不久的将来,单芯片交换容量的趋势似乎将继续保持,但一些厂商已经采用了多芯片技术,这也叫小芯片架构,其中 Serdes 在与交换核心在不同的芯片上实现,从而能够使用不同的工艺技术节点。
超51.2 Tb/s 的发展是存在高度不确定性的,将通道数加倍会继续遇到LGA/BGA 封装尺寸和触点/引脚间距的限制;200Gb/s Serdes技术还在继续研究中。因此,对于100Tb/s的研究,可能还需要更多的方案研究。
面板可插拔 (FPP) 模块是当前数据中心主要部署的。本节讨论它的优势以及相关光、电和管理接口等在未来发展上存在的的障碍。
面板可插拔(FPP)光模块的流行主要是由于以下优点。
首先,FPP 将电接口和光接口解耦,将光接口的选择从交换机组装时推迟到部署时。这使得在将光学类型与实际用例相匹配或恢复到低成本 DAC 以用于短距离(机架内)链路方面具有很大的灵活性。可插拔设备还支持增量部署(“按需付费”),其中一部分端口最初保持空置,并根据需要购买和安装额外的光学器件。
此外,由于可以从前面板处理模块,因此可以相对轻松地进行现场维修和升级。
最后,MSA实现了互操作性,并为每种类型的模块创建了一个拥有众多供应商的生态系统,避免了单源依赖,并通过规模经济降低了成本。
一个相关的部署模型是采用有源光缆(AOC),它本质上是两个(或多个)可插拔模块及其互连光缆的预制组件。这些经常出现突破一端具有单个模块的配置,该模块分为多条光纤,每条光纤在另一端都有一个单独的模块。例如,一根电缆从一个 100 Gb/s 模块分出到另一侧的四个单独的 25 Gb/s 模块,例如允许四台服务器连接到单个交换机端口。这会增加交换机扇出数并消除一些常见的错误安装,但会组织重复使用已安装的光纤。对于光模块供应商而言,AOC 消除了光学方面的互操作性问题,因此他们可以选择具有宽松操作条件的专有、成本优化的解决方案。在 InfiniBand 等高性能计算网络中,AOC 占主导地位。由于所需的范围通常不超过 100m,因此它们可以基于多模光学器件进行设计。
物理介质(PMD) 层的光接口由 IEEE 802.3 以太网标准定义。然而,特别是对于 100G 以太网一代,IEEE 标准化过程中缺乏共识导致出现了几个多源协议(MSA),包括 PSM4、CWDM4(和 CWDM4-OCP)和 CLR4。对于 400G这一代,也已经形成了几个 MSA标准,包括 CWDM8、100GLambda 和 400G-BiDi。
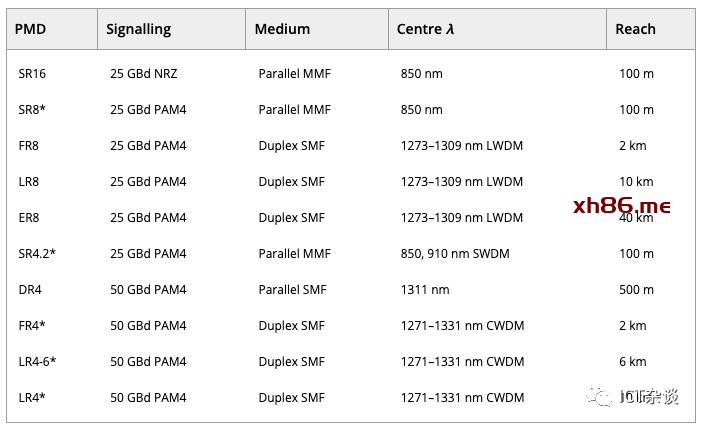
表2列出了所有直接检测光学 400G PMD。光学介质选项包括并行多模光纤 (MMF)、并行单模光纤 (SMF) 和带波分复用 (WDM) 的双工单模光纤。
尽管该表仅显示了 400G PMD,但也定义了许多使用相同通道速率但通道更少 PMD,例如 200GBASE-DR4 (4×50 Gbps) 或 100GBASE-DR1 (1×100 Gbps) 到支持在单个 400G 模块中容纳4个100GBASE-DR1 端口的突破性应用。
由于其成本优势,基于 MMF 的链路对于从架顶 (TOR) 交换机到叶交换机的上行链路很有吸引力,但其有限的范围使其不适合叶脊架构连接。400G 数据中心内连接的重点 PMD 是 DR4 和 FR4。光接口在电接口之前就已经过渡到每通道 100 Gb/s,相对于八通道光接口(例如 FR8),PMD 的复杂性减半。
400GBASE-DR4 使用四对平行光纤,在长达 500 m 的范围内更具成本效益,并提供将链路分成四个 100GBASE-DR1 的选项。DR4 非常适合 TOR 到叶的连接以及具有突破的高基数叶脊连接。另一方面,400GBASE-FR4 利用粗波分复用 (CWDM) 将光纤数量降至最低,代价是需要四个不同的激光器和波长(解)复用器。FR4 通常最适合叶-脊椎和脊椎-核心连接。
距离超过 2 公里的数据中心之间的连接需要具有更密集信道间隔 (LAN-WDM) 的更长距离直接检测链路,例如 LR 和 ER,以及相干链路(ZR,未在表中显示)。
下一代以太网很可能会标准化 800G MAC 和 800G PMD。以太网技术联盟已经提出了一个预标准的 800G 以太网 PCS/MAC 方案,但仍需要几年时间才能达成一个稳定的标准草案,包括800G PMD。但是,800G 光模块将很快以 2×400G、4×200G 或 8×100G 配置的形式出现。
第一代 800G PMD 可能基于具有并行和双工 SMF 变体的八个电通道和八个光通道,即 800GBASE-DR8 和 -FR8。基于 WDM 的版本将需要比 20 nm (CWDM) 更密集的信道间隔,例如使用 LAN-WDM 目前在 400GBASE-FR8 和 -LR8 中使用。我们仍然可能会看到基于 MMF 的 PMD,尽管它们的覆盖范围可能≤50 m,从而降低了它们的效用。
第二代 800G PMD 将基于每通道 200 Gb/s 的光调制。目前正在研究实现的技术解决方案,包括高阶调制格式,如 PAM-6 和 PAM-8。
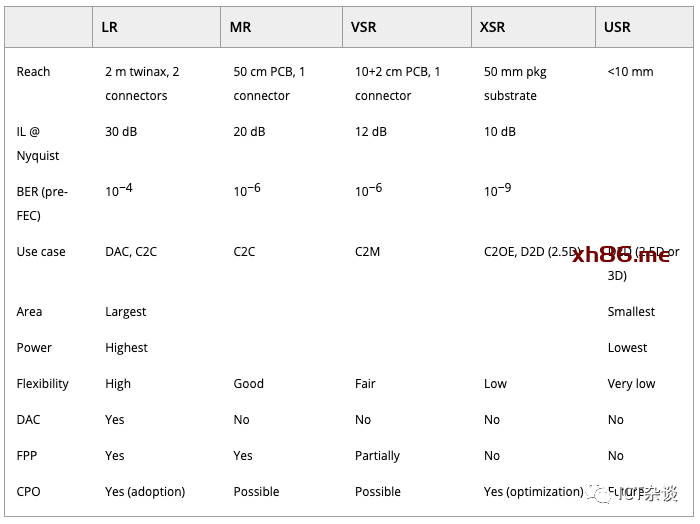
电接口通常基于光互连论坛 (OIF) 定义的通用电接口 (CEI) 实施协议,该协议构成了 IEEE 802.3 标准(例如 CAUI 和 400GAUI(以前称为 CDAUI))的基础。由于预计 CPO 的市场准入将与具有 112G 电气 serdes 的交换机 ASIC 保持一致,我们将简要回顾五种不同的电气 OIF-CEI-112G I/O 变体,如表3所示 (从左到右按递减顺序排列)。
表 3. 光互联论坛定义的 OIF-CEI-112G 链路类型
IL = 插入损耗,DAC = 直接连接铜缆,C2C = 背板芯片到芯片,C2M = 芯片到模块,C2OE = 芯片到光学引擎,D2D = 芯片到芯片
LR serdes 使铜DAC 电缆成为服务器连接的最低成本选项。只要铜仍然是机架内连接的可行选择,就需要这种类型的 Serdes。在 112 G 时,将变得很困难,因为 2 m 的目标范围不再足以覆盖某些常见用例。此范围限制对机架内的设备放置施加了限制,以最大限度地减少电缆跨度,例如将架顶式交换机移至机架中间。
MR 旨在通过一个连接器在背板上实现芯片到芯片的连接。这种类型的链路解决了用例,例如在机箱交换机中连接线卡和光纤卡(或脊和叶卡)。
VSR 主要用于芯片到模块的连接,明确寻址交换机 ASIC 和面板安装的可插拔模块之间的通道。某些端口子集可能需要重定时器,尤其是那些位于面板边缘的端口。只要必须支持可插拔光学器件,交换机 ASIC 就需要提供至少具有 VSR 范围的 Serdes。
XSR 是 Facebook 和 Microsoft 发布的 CPO 协作文档中明确调用的接口。其主要用例是在最大约 100 mm × 100 mm 的封装基板上实现芯片到光学引擎的连接。
USR 旨在作为 2.5/3D 封装解决方案的芯片到芯片接口。它可以通过更宽的接口来实现,例如 CNRZ-5、高级接口总线或线束。USR 不适用于最初的 CPO 生成,但可能适用于未来基于小芯片的交换机实现,这些交换机将交换机内核和 serdes 分布在同一封装中的多个芯片上。
光链路需要提供用于控制和管理目的的低速电接口,以提供配置和监控等功能。这通常是通过模块内部的嵌入式微控制器实现的,该微控制器提供两线接口,例如串行外设接口 (SPI) 或内部集成电路 (I2C)。QSFP 模块的管理协议在 SFF-8636 中定义,而 QSFP-DD 和 OSFP 采用了更新的通用管理接口规范 (CMIS) 。为了兼容性,CPO 引擎应遵守相同的标准。
现在是存储网络行业协会 (SNIA) 的SFF委员会监督了可插拔光学器件的 MSA 外形规格的定义,最显着的是多代小型可插拔 (SFP) 模块和 Quad SFP (QSFP) ,它将 SFP 从一个通道扩展到四个通道。QSFP+ 和 QSFP28 分别是 40 和 100 Gb/s 模块的主要外形尺寸。
向 400G 模块的过渡需要将通道数增加一倍。为了满足这一要求,出现了两种相互竞争的 MSA,QSFP-DD(双密度)和 OSFP(八进制)。QSFP-DD 稍小,并提供与 QSFP28 的向后兼容性,而 OSFP 提供更好的集成热解决方案和更好的电信号完整性,但不向后兼容(尽管 QSFP 适配器可用)。QSFP-DD 通过引入第二排触点来保持与 QSFP 的向后兼容性,代价是向电通道添加层和过孔。另一方面,OSFP 在连接器的每一侧都有更多的触点以容纳额外的通道。
两种八通道封装的功耗已经达到20 W,其中 OSFP 比 QSFP-DD 更具优势,因为它的外壳和集成散热器稍大。一个 1RU 面板可以容纳 32 到 36 个 QSFP/OSFP 模块,使用当前的 400G 模块实现每个 RU 高达 14.4 Tb/s。
对于 800G 模块一代,升级后的 QSFP-DD800 规范已经发布,预计 OSFP 也会这样做。此外,800G 可插拔 MSA 联盟也在为 800G 光学器件制定规范。
理想情况下,光和电信号速率和调制格式将始终保持一致,因此不需要速率或调制格式转换(“Gearbox”)。但是,由于交换机 ASIC 和光学路线图发展并不总是同时发生,因此可能需要进行转换。新兴的 400G 模块就是一个例证:电接口包含 8 个通道,25 GBd PAM4,但主要的光 PMD 已经是 50 GBd PAM4 的四个通道,以避免更昂贵的八通道光 PMD。这意味着每波长 100G 的光 PMD 需要模块内部的 2:1 Gearbox来在光和电通道速率之间进行转换。每通道 100G 电 Serdes 的交换机 ASIC 一出现,100G 电气通道的模块就会随之而来,例如 400G QSFP112,相反是利用现有的、成熟的、大容量的光学器件和新一代的交换芯片。一个突出的例子是 Facebook 的 Minipack 架构,它结合了 25 GBd PAM4 交换机 Serdes 和 25 GBd NRZ 光学器件。Gearbox芯片将每对交换通道转换为四个模块通道,从而能够使用传统的 100G-CWDM4-OCP QSFP28 光学器件。Minipack 的模块化特性支持未来升级到 400G QSFP-DD 光学器件。
未完待续……
4.2 成本
4.3 密度
5 移动光学内部
5.1 板载光学器件