-
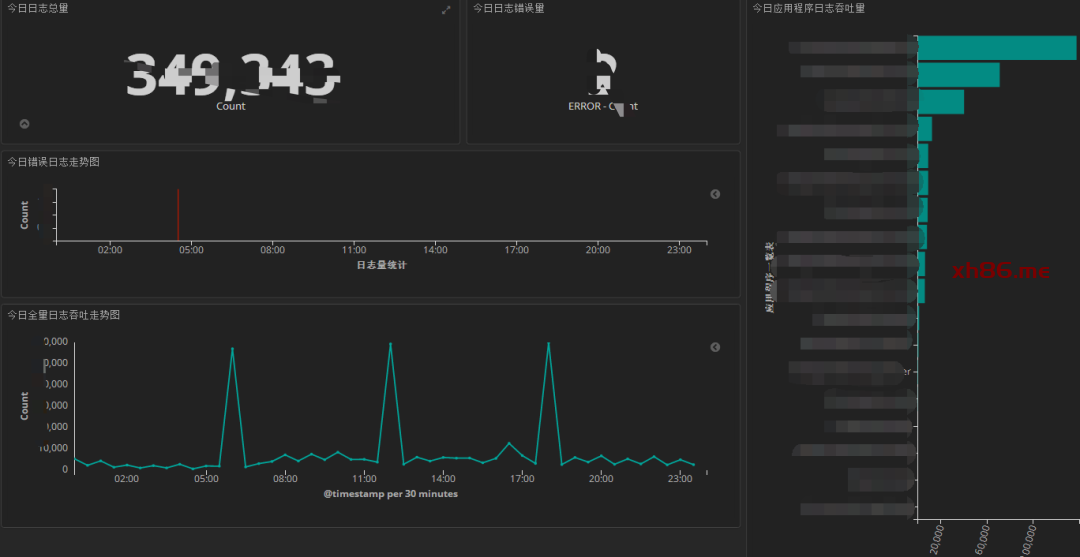
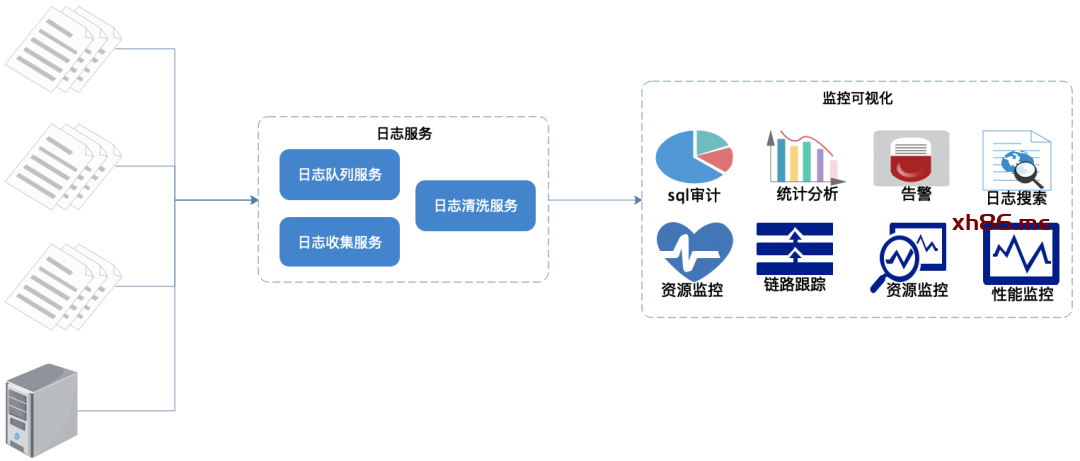
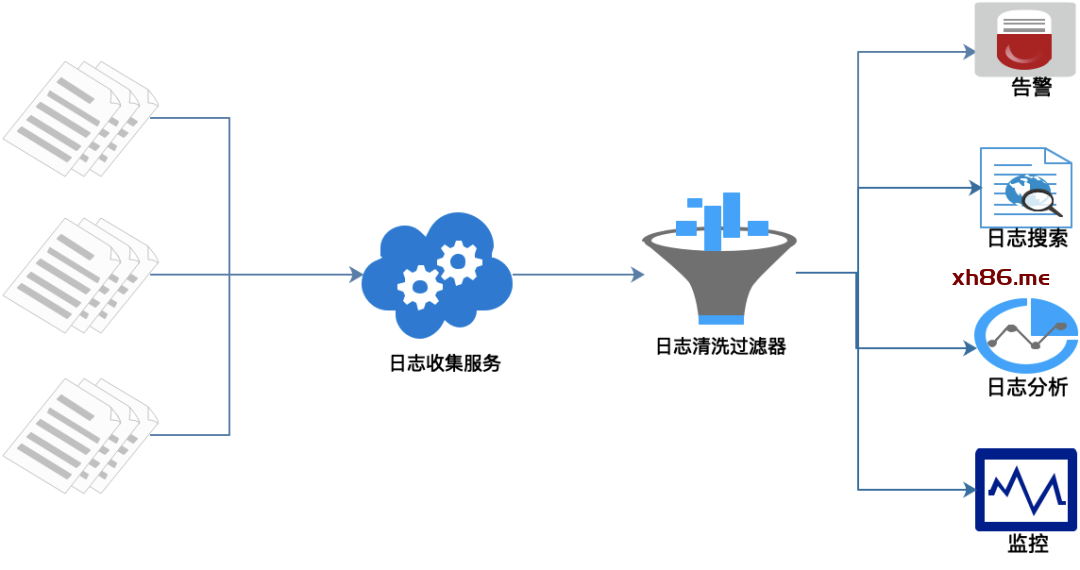
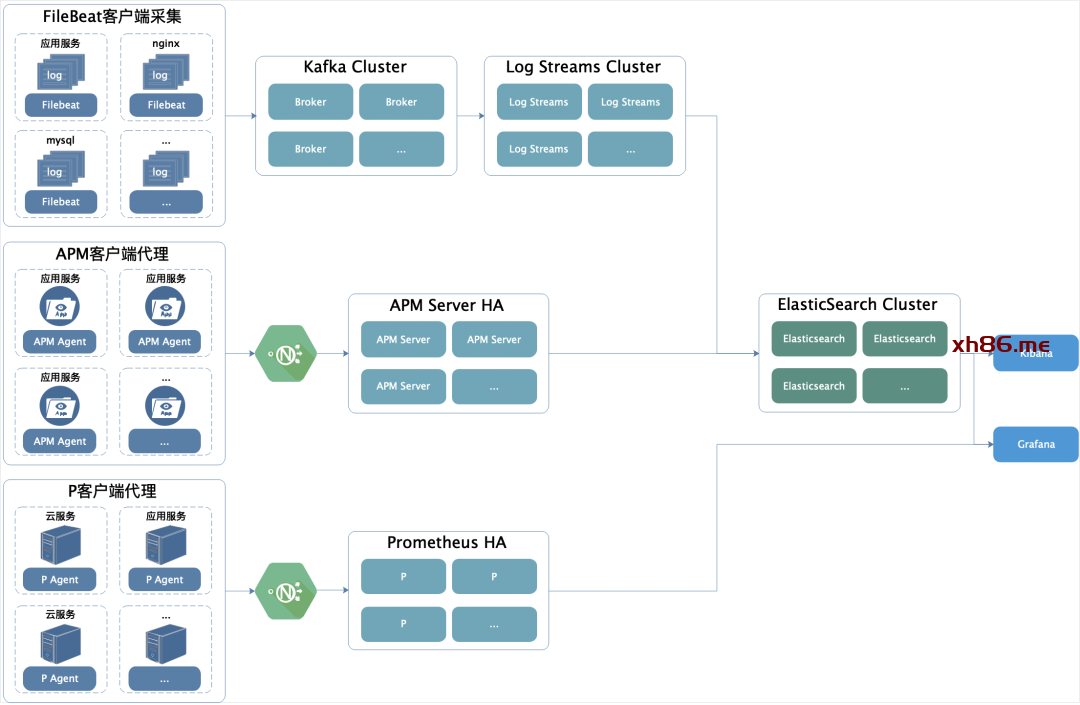
日志统一收集、过滤清洗。
-
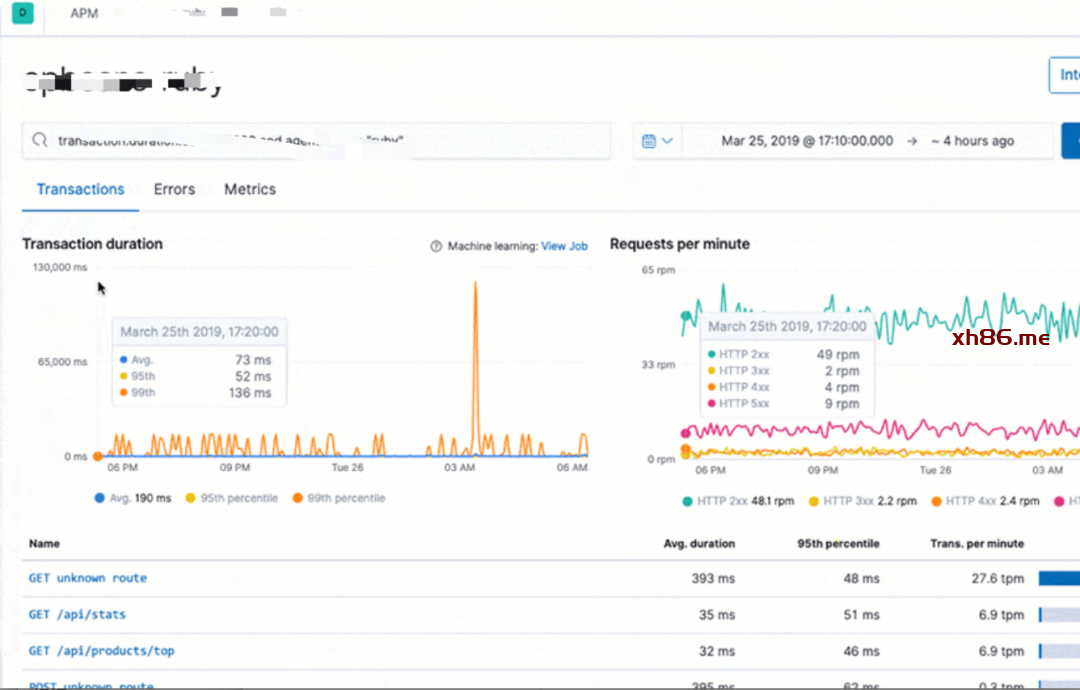
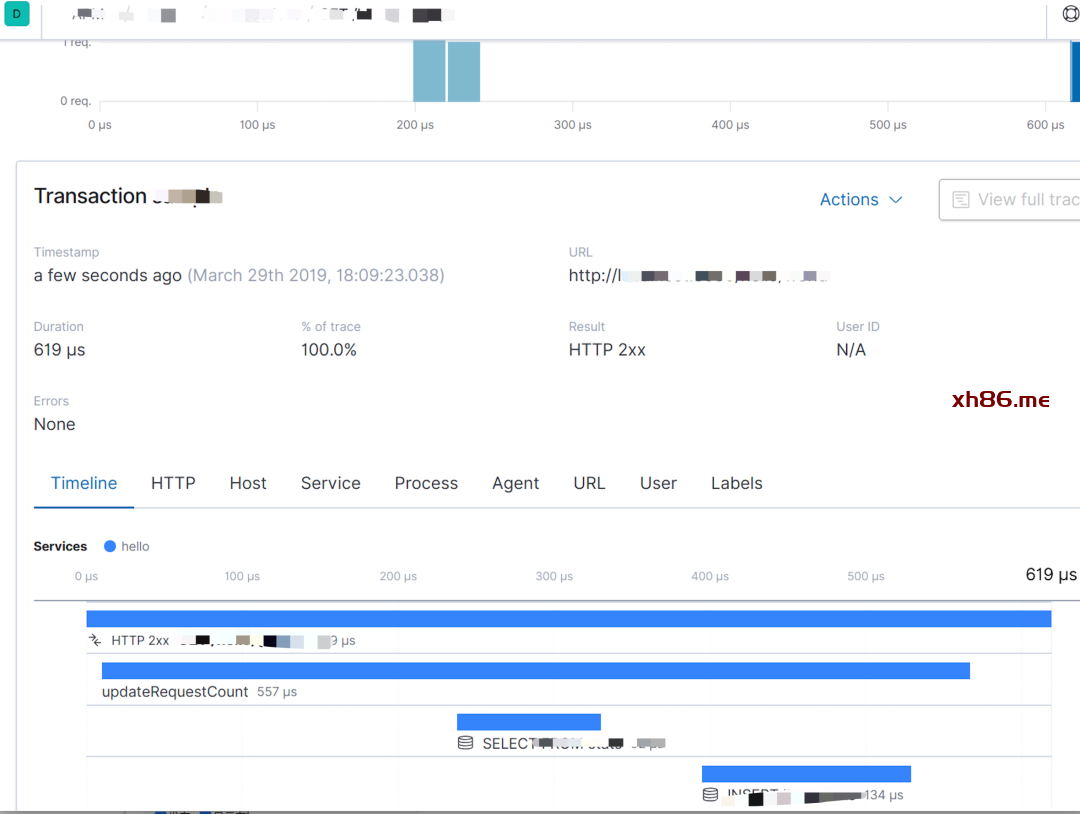
生成可视化界面、监控,告警,日志搜索。
-
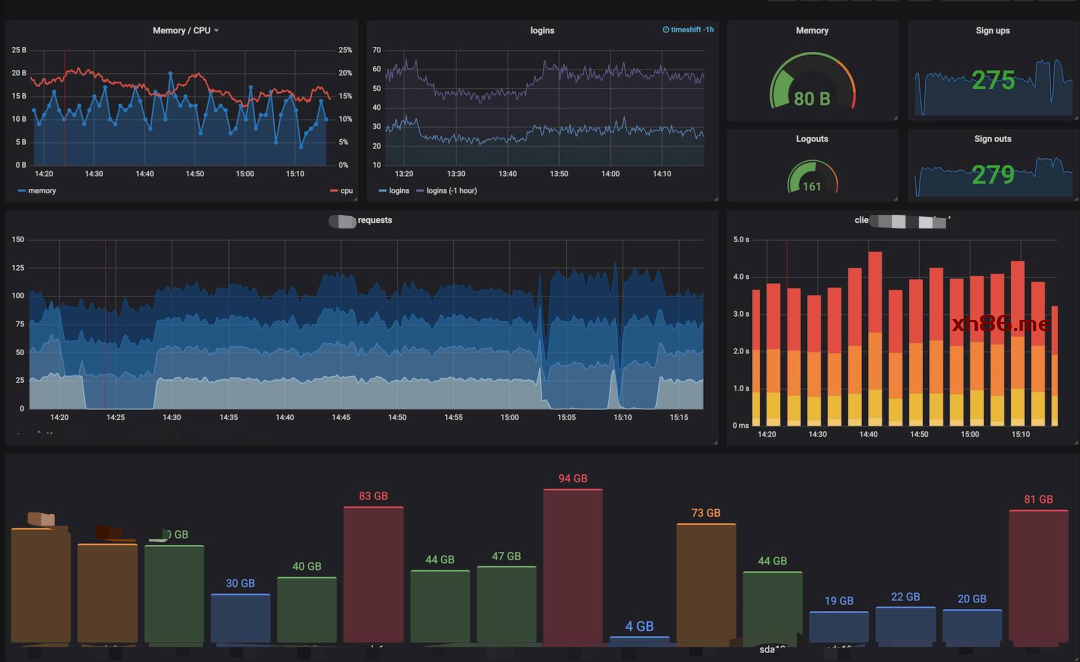
在每个服务节点上埋点,实时采集相关日志。
-
统一日志收集服务、过滤、清洗日志后生成可视化界面、告警功能。
-
界面化配置日志采集。默认 Error 级别的日志全量采集。
-
以错误时间点为中心,在流处理中开窗,辐射上下可配的 N 时间点采集非 Error 级别日志,默认只采 info 级别。
-
每个服务可配 100 个关键日志,默认关键日志全量采集。
-
在慢 SQL 的基础上,按业务分类配置不同的耗时再次过滤。
-
按业务需求实时统计业务 SQL,比如:高峰期阶段,统计一小时内同类业务 SQL 的查询频率。可为 DBA 提供优化数据库的依据,如按查询的 SQL 创建索引。
-
高峰时段按业务类型的权重指标、日志等级指标、每个服务在一个时段内日志最大限制量指标、时间段指标等动态清洗过滤日志。
-
根据不同的时间段动态收缩时间窗口。
-
日志索引生成规则:按服务生成的日志文件规则生成对应的 index,比如:某个服务日志分为:debug、info、error、xx_keyword,那么生成的索引也是 debug、info、error、xx_keyword 加日期作后缀。这样做的目的是为研发以原习惯性地去使用日志。