
-
从最简单的开始:单体架构
-
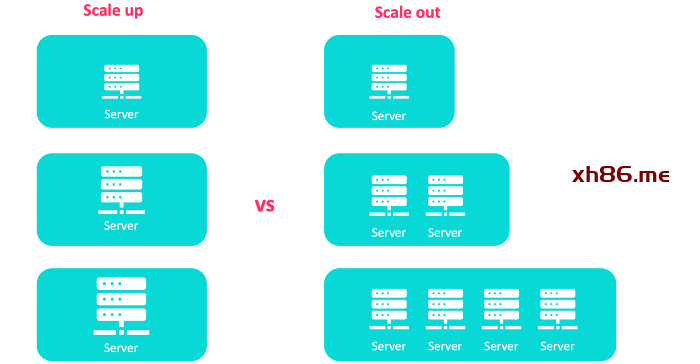
可伸缩性的艺术:水平扩展(scaling out),纵向扩展(scaling up)
-
关系型数据库的可扩展性:主从备份、主主备份、联合、分片、去规范化和 SQL 调优
-
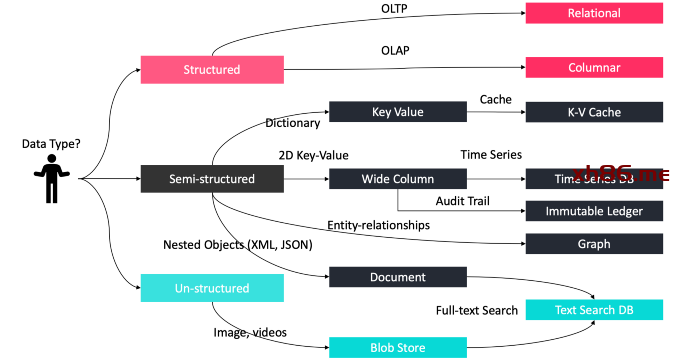
数据库选型:NoSQL 还是 SQL?
-
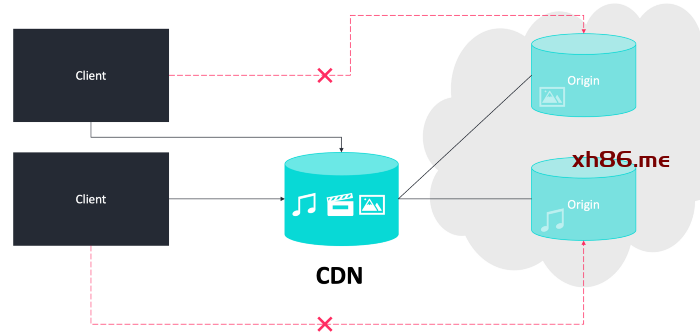
高级概念:缓存、CDN、GeoDNS 等

-
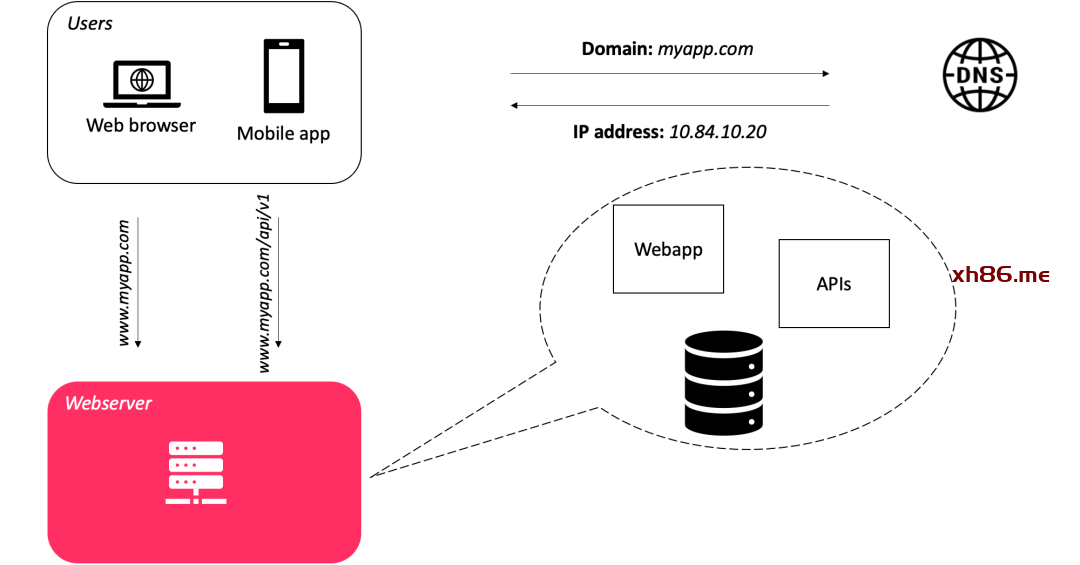
如果发生数据库故障,则会导致系统故障。
-
如果 Web 服务器出现故障,也会导致整个系统故障。
-
通过增加 RAID 中的硬盘,增加 I/O 容量。
-
通过切换到固态驱动器(SSD)来改善 I/O 访问时间。
-
切换到具有更多处理器的服务器。
-
通过升级网络接口或安装额外的网络接口,提高网络吞吐量。
-
通过增加内存来减少 I/O 操作。
-
“不可能无限制的给一台服务器增加硬件”。能够增加多少硬件主要取决于操作系统和服务器的内存总线宽度。
-
当我们增加内存或者其他硬件时,必须关闭服务器,因此,如果系统只有一台服务器,停机是不可避免的。
-
功能强大的机器通常比流行的硬件贵很多。
-
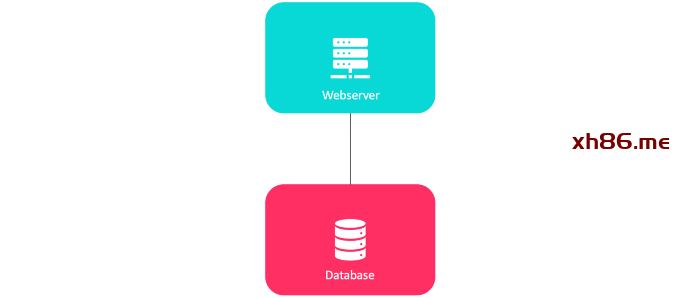
Web 服务器与数据库服务器的调优方式不同。
-
Web 服务器需要更好的 CPU,而数据库服务器需要更多内存。
-
为 Web 层和数据层使用独立的服务器可以让它们独立扩展。
-
增加服务器数量意味着需要维护更多的资源。
-
系统的代码也需要更改,从而支持并行处理,以及在多个服务器之间分配工作。
-
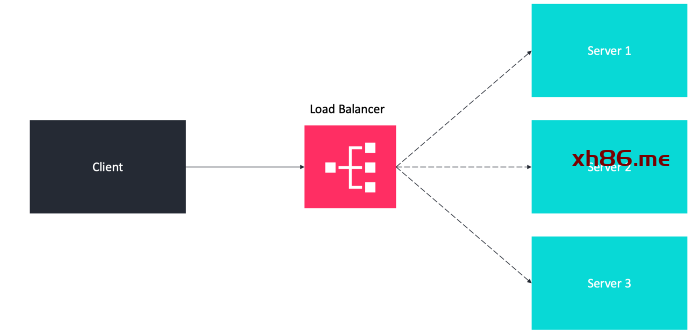
如果服务器 1 下线,所有流量将路由到服务器 2 和服务器 3,因此网站服务不会下线。我们需要向服务器池中添加一个新的健康服务器,以平衡负载。
-
当流量快速增长时,只需要向 Web 服务器池中添加更多的服务器,负载均衡器就会自动路由流量。
-
轮询(Round robin):每个服务器按照类似先进先出(FIFO)的顺序接收请求。
-
最少连接数(Least number of connections):将请求路由到连接数最少的服务器。
-
最快响应时间(Fastest response time):将请求路由到响应时间最快(通过最近一段时间采样或统计最多次数)的服务器。
-
加权(Weighted):更强大的服务器将比较弱的服务器接收到更多的请求。
-
IP 哈希(IP Hash):计算客户端的 IP 地址的哈希值,将请求重定向到服务器。
-
可以在共享 IP 池中添加和删除服务器,立即生效。
-
负载均衡可以按设计需求进行。
-
L4 负载均衡器:基于 TCP 在网络层提供的信息,通常不查看请求的内容就选择服务器。
-
L7 负载均衡器:请求可以基于查询字符串、cookie 或我们选择的任何报头中的信息,以及包括源和目的地址等常规信息进行负载均衡。
-
备份(Replication)通常指的是一种允许我们在不同的机器上存储相同数据的多个副本的技术。
-
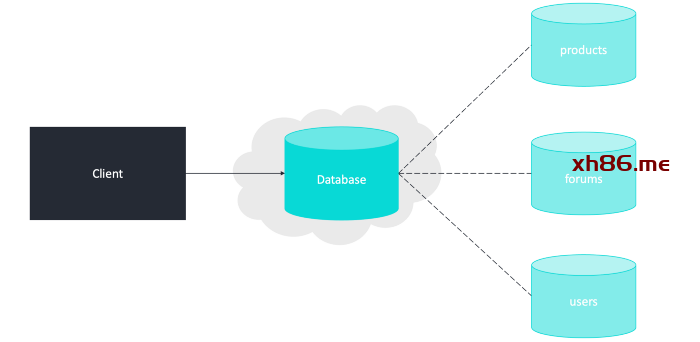
联合(Federation)(或功能分区)按功能对数据库进行分割。
-
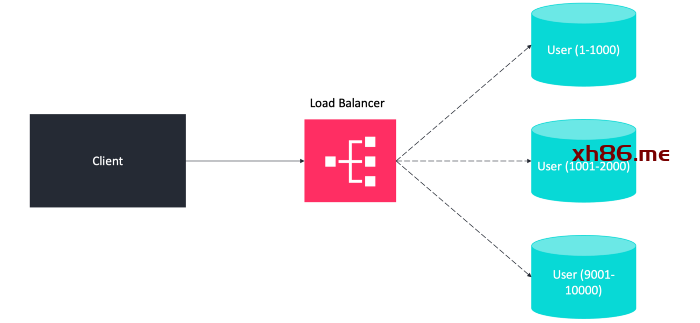
分片(Sharding)是一种与分区相关的数据库架构模式,将数据的不同部分放到不同的服务器上,不同的用户将访问数据的不同部分。
-
去规格化(Denormalization)试图以牺牲部分写性能为代价来提高读性能,通过在多个表中写入数据来避免昂贵的数据 joins 操作。
-
SQL 调优(SQL tuning)
-
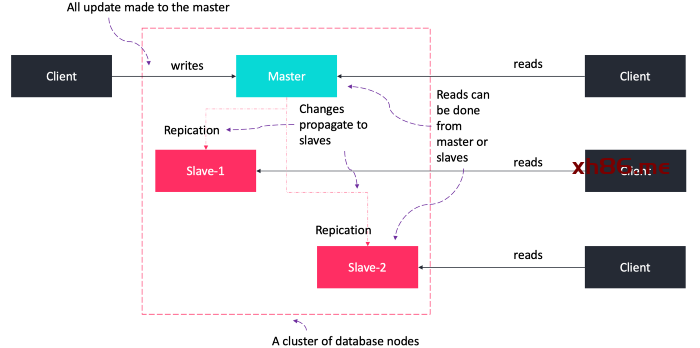
客户端连接到主服务器并更新数据。
-
数据将同步到从服务器,直到所有数据在所有服务器上保持一致。
-
如果主服务器由于某种原因宕机,数据仍然可以通过从服务器获取,但是不能进行新的写操作。
-
需要额外的算法将从服务器切换为主服务器。
-
同步解决方案(Synchronous solutions):只有在所有服务器都接受之后,才正式提交数据修改事务(分布式事务),因此故障恢复的时候不会丢失数据。
-
异步解决方案(Asynchronous solutions):提交->延迟->扩散到集群中的其他服务器,因此一些数据更新可能在故障恢复时丢失。
-
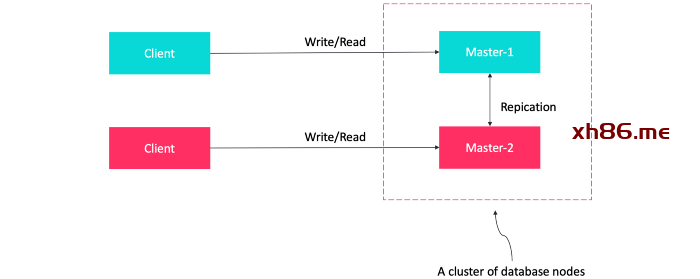
如果一台主服务器出现故障,其他数据库服务器可以正常运行并填补漏洞。当失效的数据库服务器重新上线时,它将复制最新的数据从而和其他服务器同步。
-
主服务器可以位于多个不同的物理位置,可以分布在整个网络中。
-
受限于主服务器处理数据更新的能力。
-
每个用户只需要与一个服务器通信,因此可以从该服务器获得快速响应。
-
负载可以在服务器之间很好地平衡——例如,如果我们有 5 台服务器,每个服务器只需要处理 20% 的负载。
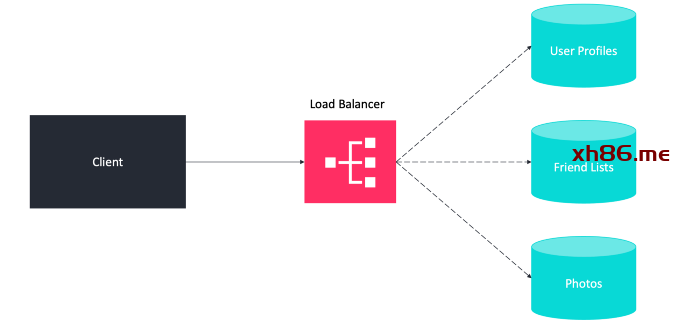
-
在某些情况下,数据库 joins 操作变得更加昂贵,甚至是不可行的。
-
分片会损害数据库的引用完整性。
-
数据库 schema 的更改可能会非常昂贵。
-
数据分布可能不均匀,一个分片上可能有过多负载。
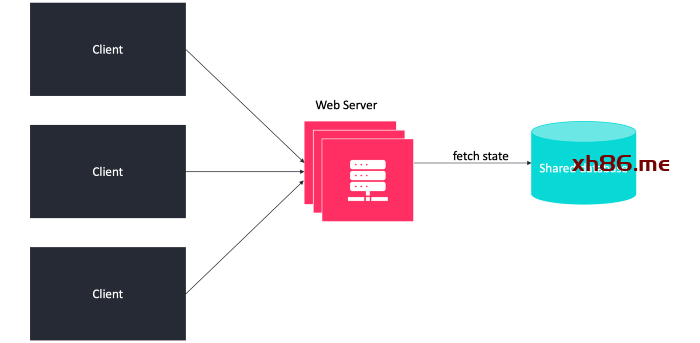

-
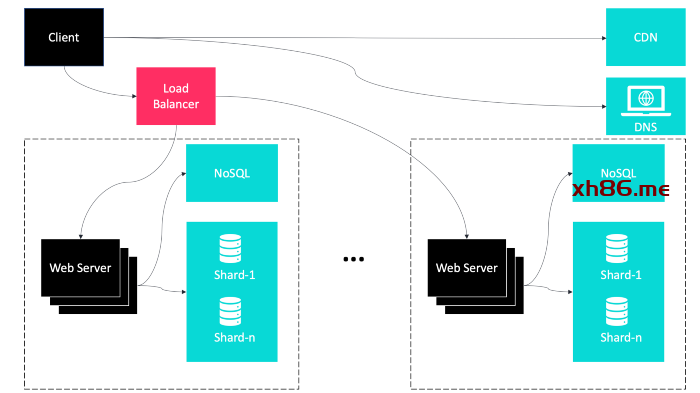
数据分片和备份的融合
-
长轮询 vs WebSockets VS 服务器事件
-
索引和代理
-
SQL 调优
-
弹性计算