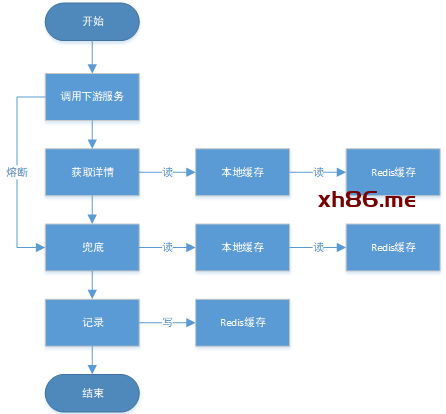
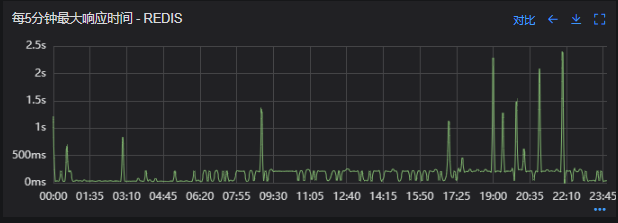
-
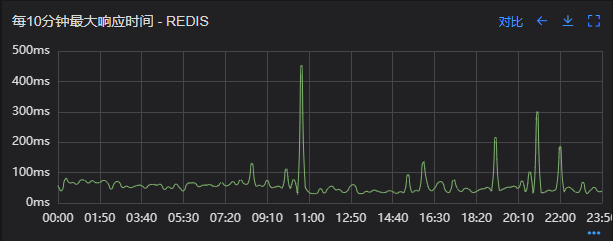
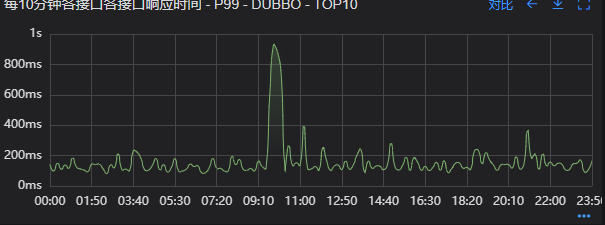
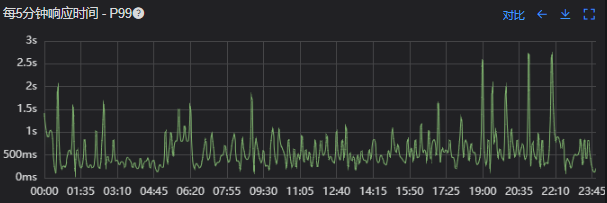
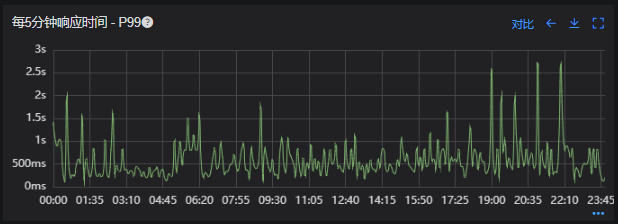
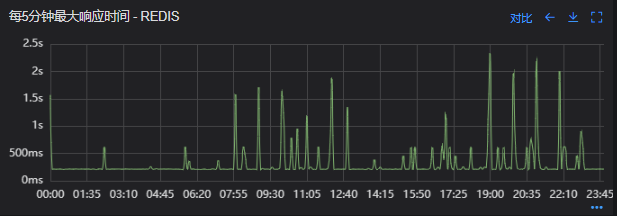
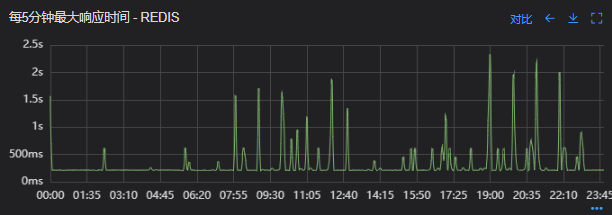
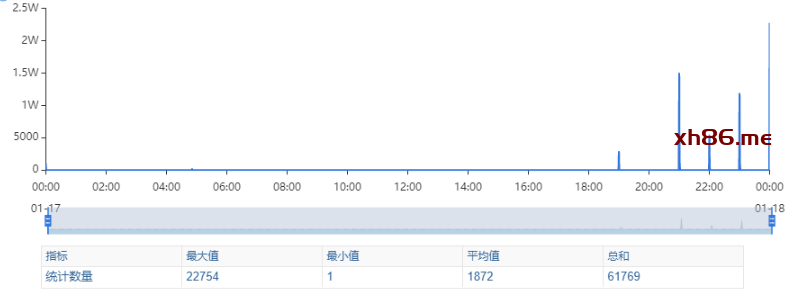
出现了慢查询
-
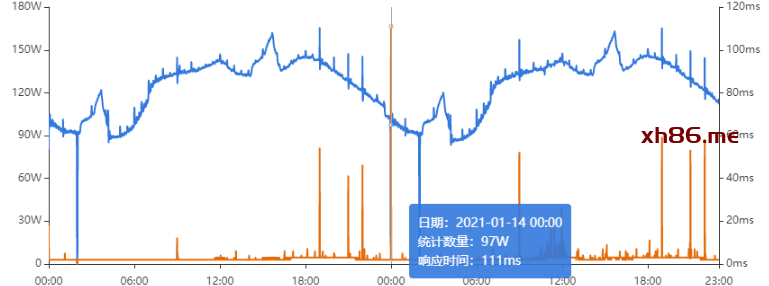
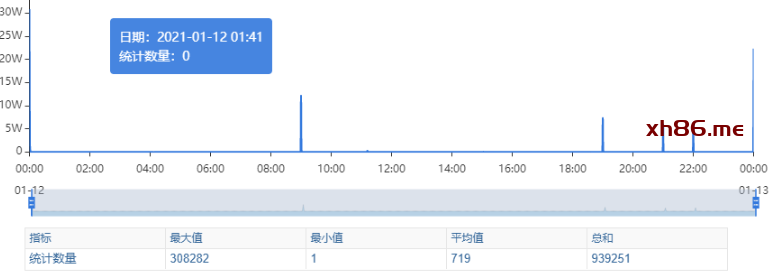
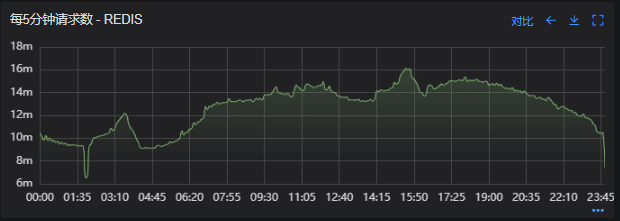
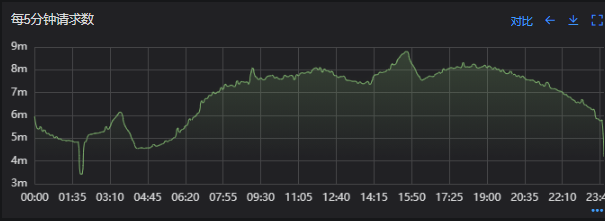
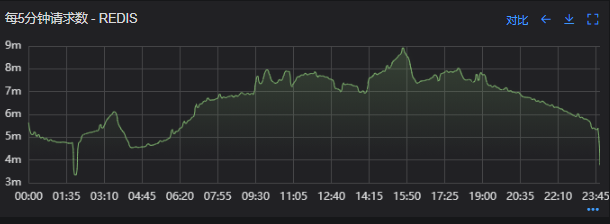
Redis服务出现性能瓶颈
-
客户端配置不合理


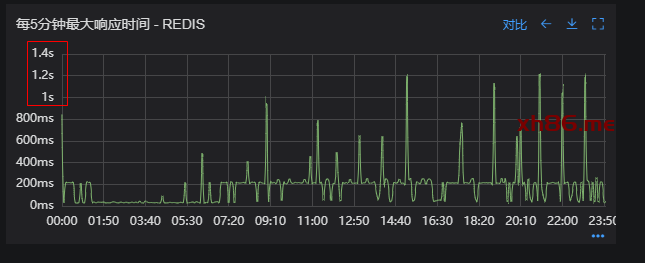
1、setEx
public String setex(final byte[] key, final int seconds, final byte[] value) {
return new JedisClusterCommand<String>(connectionHandler, maxAttempts) {
@Override
public String execute(Jedis connection) {
return connection.setex(key, seconds, value);
}
}.runBinary(key);
}
2、runBinary
public T runBinary(byte[] key) {
if (key == null) {
throw new JedisClusterException(“No way to dispatch this command to Redis Cluster.”);
}
return runWithRetries(key, this.maxAttempts, false, false);
}
3、runWithRetries
private T runWithRetries(byte[] key, int attempts, boolean tryRandomNode, boolean asking) {
if (attempts <= 0) {
throw new JedisClusterMaxRedirectionsException(“Too many Cluster redirections?”);
}
Jedis connection = null;
try {
if (asking) {
// TODO: Pipeline asking with the original command to make it
// faster….
connection = askConnection.get();
connection.asking();
// if asking success, reset asking flag
asking = false;
} else {
if (tryRandomNode) {
connection = connectionHandler.getConnection();
} else {
connection = connectionHandler.getConnectionFromSlot(JedisClusterCRC16.getSlot(key));
}
}
return execute(connection);
}
4、getConnectionFromSlot
public Jedis getConnectionFromSlot(int slot) {
JedisPool connectionPool = cache.getSlotPool(slot);
if (connectionPool != null) {
// It can‘t guaranteed to get valid connection because of node
// assignment
return connectionPool.getResource();
} else {
renewSlotCache(); //It’s abnormal situation for cluster mode, that we have just nothing for slot, try to rediscover state
connectionPool = cache.getSlotPool(slot);
if (connectionPool != null) {
return connectionPool.getResource();
} else {
//no choice, fallback to new connection to random node
return getConnection();
}
}
}
public T borrowObject(final long borrowMaxWaitMillis) throws Exception {
assertOpen();
final AbandonedConfig ac = this.abandonedConfig;
if (ac != null && ac.getRemoveAbandonedOnBorrow() &&
(getNumIdle() < 2) &&
(getNumActive() > getMaxTotal() – 3) ) {
removeAbandoned(ac);
}
PooledObject<T> p = null;
// Get local copy of current config so it is consistent for entire
// method execution
final boolean blockWhenExhausted = getBlockWhenExhausted();
boolean create;
final long waitTime = System.currentTimeMillis();
while (p == null) {
create = false;
p = idleObjects.pollFirst();
if (p == null) {
p = create();
if (p != null) {
create = true;
}
}
if (blockWhenExhausted) {
if (p == null) {
if (borrowMaxWaitMillis < 0) {
p = idleObjects.takeFirst();
} else {
p = idleObjects.pollFirst(borrowMaxWaitMillis,
TimeUnit.MILLISECONDS);
}
}
if (p == null) {
throw new NoSuchElementException(
“Timeout waiting for idle object”);
}
} else {
if (p == null) {
throw new NoSuchElementException(“Pool exhausted”);
}
}
if (!p.allocate()) {
p = null;
}
if (p != null) {
try {
factory.activateObject(p);
} catch (final Exception e) {
try {
destroy(p);
} catch (final Exception e1) {
// Ignore – activation failure is more important
}
p = null;
if (create) {
final NoSuchElementException nsee = new NoSuchElementException(
“Unable to activate object”);
nsee.initCause(e);
throw nsee;
}
}
if (p != null && (getTestOnBorrow() || create && getTestOnCreate())) {
boolean validate = false;
Throwable validationThrowable = null;
try {
validate = factory.validateObject(p);
} catch (final Throwable t) {
PoolUtils.checkRethrow(t);
validationThrowable = t;
}
if (!validate) {
try {
destroy(p);
destroyedByBorrowValidationCount.incrementAndGet();
} catch (final Exception e) {
// Ignore – validation failure is more important
}
p = null;
if (create) {
final NoSuchElementException nsee = new NoSuchElementException(
“Unable to validate object”);
nsee.initCause(validationThrowable);
throw nsee;
}
}
}
}
}
updateStatsBorrow(p, System.currentTimeMillis() – waitTime);
return p.getObject();
}
-
是否有空闲连接,有空闲连接就直接返回,没有就创建。
-
创建时如果超出最大连接数,则判断是否有其他线程在创建连接,如果没则直接返回,如果有则等待maxWaitMis时间(其他线程可能创建失败),如果未超出最大连接,则执行创建连接操作(此时获取连接等待时间可能会大于maxWaitMs)。
-
如果创建不成功,则判断是否是阻塞获取连接,如果不是则直接抛出异常,连接池不够用,如果是则判断maxWaitMillis是否小于0,如果小于0则阻塞等待,如果大于0则阻塞等待maxWaitMillis。
-
后续就是根据参数来判断是否需要做连接check等。
public GenericObjectPool(final PooledObjectFactory<T> factory,
final GenericObjectPoolConfig<T> config) {
super(config, ONAME_BASE, config.getJmxNamePrefix());
if (factory == null) {
jmxUnregister(); // tidy up
throw new IllegalArgumentException(“factory may not be null”);
}
this.factory = factory;
idleObjects = new LinkedBlockingDeque<>(config.getFairness());
setConfig(config);
}
1、初始化连接池
public GenericObjectPool(PooledObjectFactory<T> factory,
GenericObjectPoolConfig config) {
super(config, ONAME_BASE, config.getJmxNamePrefix());
if (factory == null) {
jmxUnregister(); // tidy up
throw new IllegalArgumentException(“factory may not be null”);
}
this.factory = factory;
idleObjects = new LinkedBlockingDeque<PooledObject<T>>(config.getFairness());
setConfig(config);
startEvictor(getTimeBetweenEvictionRunsMillis());
}
1、final void startEvictor(long delay) {
synchronized (evictionLock) {
if (null != evictor) {
EvictionTimer.cancel(evictor);
evictor = null;
evictionIterator = null;
}
if (delay > 0) {
evictor = new Evictor();
EvictionTimer.schedule(evictor, delay, delay);
}
}
}
2、class Evictor extends TimerTask {
/**
* Run pool maintenance. Evict objects qualifying for eviction and then
* ensure that the minimum number of idle instances are available.
* Since the Timer that invokes Evictors is shared for all Pools but
* pools may exist in different class loaders, the Evictor ensures that
* any actions taken are under the class loader of the factory
* associated with the pool.
*/
@Override
public void run() {
ClassLoader savedClassLoader =
Thread.currentThread().getContextClassLoader();
try {
if (factoryClassLoader != null) {
// Set the class loader for the factory
ClassLoader cl = factoryClassLoader.get();
if (cl == null) {
// The pool has been dereferenced and the class loader
// GC‘d. Cancel this timer so the pool can be GC’d as
// well.
cancel();
return;
}
Thread.currentThread().setContextClassLoader(cl);
}
// Evict from the pool
try {
evict();
} catch(Exception e) {
swallowException(e);
} catch(OutOfMemoryError oome) {
// Log problem but give evictor thread a chance to continue
// in case error is recoverable
oome.printStackTrace(System.err);
}
// Re-create idle instances.
try {
ensureMinIdle();
} catch (Exception e) {
swallowException(e);
}
} finally {
// Restore the previous CCL
Thread.currentThread().setContextClassLoader(savedClassLoader);
}
}
}
3、 void ensureMinIdle() throws Exception {
ensureIdle(getMinIdle(), true);
}
4、 private void ensureIdle(int idleCount, boolean always) throws Exception {
if (idleCount < 1 || isClosed() || (!always && !idleObjects.hasTakeWaiters())) {
return;
}
while (idleObjects.size() < idleCount) {
PooledObject<T> p = create();
if (p == null) {
// Can‘t create objects, no reason to think another call to
// create will work. Give up.
break;
}
if (getLifo()) {
idleObjects.addFirst(p);
} else {
idleObjects.addLast(p);
}
}
if (isClosed()) {
// Pool closed while object was being added to idle objects.
// Make sure the returned object is destroyed rather than left
// in the idle object pool (which would effectively be a leak)
clear();
}
}