索引用于快速找出在某个列中有一特定值的行,如果不使用索引MySQL必须从第l条记录开始读完整个表,直到找出相关的行.表越大,查询数据所花费的时间越多,如果表中查询的列有一个索引,MySQL能快速到达某个位置去搜寻数据文件,而不必查看所有数据,可加快数据查询的查询速度提高效率,索引可在创建表时增加,也可动态调整已有表.
该笔记文字描述部分整理于《MySQL 5.7从入门到精通》其目的是总结通用知识点,学习时总结的笔记,以及常用SQL语句的写法模板,方便后期查阅与工作时使用。
通俗的来说索引是一种数据结构,是帮助MySQL进行高效检索数据的一种机制,你可以简单理解为排好序的快速查找数据结构,
索引都是B+树(多路搜索树)结构组织的索引,包括聚集索引,复合索引,前缀索引,唯一索引,都是b+树索引.
优势:1.提高数据检索效率,降低数据库IO成本,降低CPU消耗。
劣势: 2.索引是一张表,索引也占空间,虽然提高了查询速度,但也会降低表的更新速度,如果新加数据,索引也会自动更新。
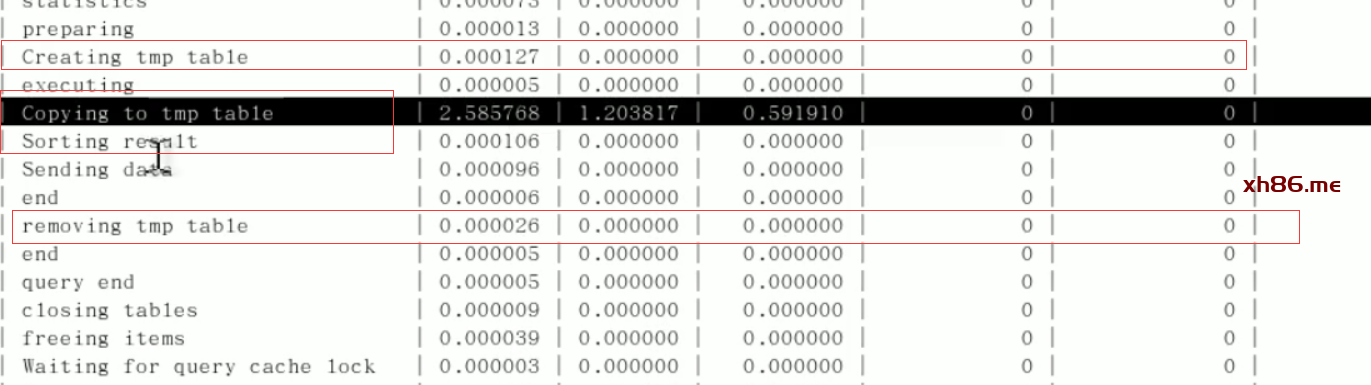
CPU在饱和的时候一般发生在数据装入内存或从磁盘上读取数据时。
IO磁盘平静,服务器硬件平静。
创建普通索引: 在创建表时指定索引类型,如下在u_id字段添加一个普通索引,该索引作用只是加对快数据的访问速度.
MariaDB [lyshark]> create table book
-> (
-> u_id int not null,
-> u_book varchar(20) not null,
-> index(u_id)
-> );
— 使用show index语句查看指定表中创建的索引
MariaDB [lyshark]> show index from book;
MariaDB [lyshark]> show create table book \G;
MariaDB [lyshark]> explain select * from book where u_id=1 \G;
创建唯一索引: 创建唯一索引的主要原因是减少查询索引列操作的执行时间,尤其是对比较庞大的数据表.它与前面的普通索引类似,不同的就是:索引列的值必须唯一,但允许有空值.如果是组合索引,则列值的组合必须唯一.
MariaDB [lyshark]> create table table_1
-> (
-> id int not null,
-> name char(30) not null,
-> unique index UniqIdx(id)
-> );
Query OK, 0 rows affected (0.02 sec)
MariaDB [lyshark]> show create table table_1 \G;
*************************** 1. row ***************************
Table: table_1
Create Table: CREATE TABLE `table_1` (
`id` int(11) NOT NULL,
`name` char(30) NOT NULL,
UNIQUE KEY `UniqIdx` (`id`) #id字段已经成功建立了一个名为UniqIdx的唯一索引
) ENGINE=InnoDB DEFAULT CHARSET=latin1
1 row in set (0.00 sec)
创建单列索引: 单列索引是在数据表中的某一个字段上创建的索引,一个表中可以创建多个单列索引.前面两个例子中创建的索引都为单列索引.
MariaDB [lyshark]> create table table_2
-> (
-> id int not null,
-> name char(50) null,
-> index SingleIdx(name(20))
-> );
Query OK, 0 rows affected (0.03 sec)
MariaDB [lyshark]> show create table table_2 \G;
*************************** 1. row ***************************
Table: table_2
Create Table: CREATE TABLE `table_2` (
`id` int(11) NOT NULL,
`name` char(50) DEFAULT NULL,
KEY `SingleIdx` (`name`(20)) #name字段上已经成功建立了一个单列索引,名称为SingleIdx
) ENGINE=InnoDB DEFAULT CHARSET=latin1
1 row in set (0.00 sec)
创建组合索引: 组合索引就是在多个字段上创建多个索引.
MariaDB [lyshark]> create table table_3
-> (
-> id int not null,
-> name char(30) not null,
-> age int not null,
-> info varchar(255),
-> index MultiIdx(id,name,age)
-> );
创建全文索引: 全文索引可以用于全文搜索,全文索引适合用于大型数据集,目前只有MyISAM存储引擎支持FULLTEXT索引,并且只为CHAR、VARCHAR和TEXT列创建索引.索引总是对整个列进行,不支持局部(前缀)索引.
— 注意:MySQL5.7默认存储引擎室是InnoDB,在这里我们要改成MyISAM,不然索引会报错
MariaDB [lyshark]> create table table_4(
-> id int not null,
-> name char(40) not null,
-> age int not null,
-> info varchar(255),
-> fulltext index FullTxtIdx(info)
-> )engine=MyISAM;
创建空间索引: 空间索引必须在MyISAM类型的表中创建,且空间类型的字段必须为空,可以看到,table_5表的g字段上创建了名称为spatIdex的空间索引,注意:创建时间指定空间类型字段值的非空约束,并且表的存储引擎必须为MyISAM.
MariaDB [lyshark]> create table table_5
-> (
-> g geometry not null,
-> spatial index spatIdx(g)
-> )engine=MyISAM;
添加索引: 上面的几种形式都是在新建表中添加索引,如果需要在已存在表中添加则需要使用以下命令了.
MariaDB [lyshark]> create table book
-> (
-> bookid int not null,
-> bookname varchar(255) not null,
-> authors varchar(255) not null,
-> info varchar(255) null,
-> comment varchar(255) null,
-> year_public year not null
-> );
— 添加普通索引
MariaDB [lyshark]> alter table book add index BKNameIdx(bookname(30));
— 添加唯一索引
MariaDB [lyshark]> alter table book add unique index UniqidIdx(bookId);
— 添加单列索引
MariaDB [lyshark]> alter table book add index BkcmtIdx(comment(50));
— 添加组合索引
MariaDB [lyshark]> alter table book add index BkAuAndInfoIdx(authors(30),info(50));
— 通过索引名字删除索引
MariaDB [lyshark]> alter table book drop index UniqidIdx;
MariaDB [lyshark]> alter table book drop index BKNameIdx;
explain 字段的情况:
MariaDB [lyshark]> explain select s_name,s_city from suppliers where s_id IN (select Gid from lyshark where Uid=’a1′);
+——+————-+———–+——-+—————+———+———+——-+——+——-+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+——+————-+———–+——-+—————+———+———+——-+——+——-+
| 1 | PRIMARY | lyshark | const | PRIMARY | PRIMARY | 30 | const | 1 | |
| 1 | PRIMARY | suppliers | const | PRIMARY | PRIMARY | 4 | const | 1 | |
+——+————-+———–+——-+—————+———+———+——-+——+——-+
MariaDB [lyshark]> explain select Course.CID,Course.Cname from Course join(
select CID from lyshark.StudentScore where SID = (select SID from lyshark.Student where Sname=’周梅’)
)as StudentScore on Course.CID = StudentScore.CID;
+———+————-+————–+——+—————+——+———+——+——+———-+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+———+————-+————–+——+—————+——+———+——+——+———-+
| 1(1) | SIMPLE | Course | ALL | NULL | NULL | NULL | NULL | 3 | |
| 1(2) | SIMPLE | StudentScore | ALL | NULL | NULL | NULL | NULL | 18 | |
| 3 | SUBQUERY | Student | ALL | NULL | NULL | NULL | NULL | 10 | |
+———+————-+————–+——+—————+——+———+——+——+———-+
ID字段的理解:
1.当ID字段相同的情况下执行数据是从上到下,例如第一张表中会由上至下执行下来.
2.当ID不同的情况,如果是子查询,id越大的将在最前面被执行,例如第二张表执行顺序为3->1(1)->1(2)
select_type
MariaDB [lyshark]> explain select * from tbl_emp a left join tbl_dept b on a.deptld=b.id where b.id is null
-> union
-> select * from tbl_emp a right join tbl_dept b on a.deptld = b.id where a.deptld is null;
+——+————–+————+——–+—————+———+———+——————+——+———+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+——+————–+————+——–+—————+———+———+——————+——+———+
| 1 | PRIMARY | a | ALL | NULL | NULL | NULL | NULL | 8 | |
| 1 | PRIMARY | b | eq_ref | PRIMARY | PRIMARY | 4 | lyshark.a.deptld | 1 | |
| 2 | UNION | b | ALL | NULL | NULL | NULL | NULL | 5 | |
| 2 | UNION | a | ALL | fk_dept_id | NULL | NULL | NULL | 8 | |
| NULL | UNION RESULT | <union1,2> | ALL | NULL | NULL | NULL | NULL | NULL | |
+——+————–+————+——–+—————+———+———+——————+——+———+
SIMPLE => 标志着简单的select查询请求,查询中不包含子查询或者union查询.
PRIMARY => 查询中任何复杂的查询中,最外层的查询语句,就是最后加载的语句.
SUBQUERY => 子查询类型,在select或where列表中包含了子查询.
DERIVED => 在FROM列表中包含子查询,会被标记为DERIVED(衍生),此时会递归执行子查询,并存储在临时表中.
UNION => 若第二个SELECT出现在UNION之后,则标记为UNION.
UNION RESULT => 从UNION表中获取结果的SELECT
type 访问类型排列,只要能够达到ref,range级别就已经不错了,性能效率。
system -> const -> eq_ref -> ref -> range ->index -> all
system -> 表中只有一条记录,这是const类型的特里,平时不会出现。
const -> 主键唯一索引:表示通过索引一次就找到数据,例如查询一个常量。
MariaDB [lyshark]> explain select * from lyshark where Uid=”a1″;
+——+————-+———+——-+—————+———+———+——-+——+——-+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+——+————-+———+——-+—————+———+———+——-+——+——-+
| 1 | SIMPLE | lyshark | const | PRIMARY | PRIMARY | 30 | const | 1 | |
+——+————-+———+——-+—————+———+———+——-+——+——-+
eq_ref -> 唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配,常用于主键或唯一索引扫描。
ref-> 非唯一性索引扫描,返回匹配某个单独值的所有行,被之上也是一种索引访问。查找扫描混合体
MariaDB [lyshark]> create table t1(col1 int,col2 int);
MariaDB [lyshark]> alter table t1 add index idx_col1_col2(col1,col2);
MariaDB [lyshark]> explain select * from t1 where col1=1;
+——+————-+——-+——+—————+—————+———+——-+——+——–+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+——+————-+——-+——+—————+—————+———+——-+——+——–+
| 1 | SIMPLE | t1 | ref | idx_col1_col2 | idx_col1_col2 | 5 | const | 1 | |
+——+————-+——-+——+—————+—————+———+——-+——+——–+
range -> 范围扫描,只检索给定范围的行,key列显示使用了那个索引。 where,between,<>,in 等查询中使用。
explain select * from t1 where col1 between 1 and 2;
explain select * from t1 where col1 in (1,2,3);
index -> 全索引扫描,全表索引扫描,比all要好一些。
MariaDB [lyshark]> explain select * from t1;
all -> 全表扫描。最差的性能。
possible_keys,key 是否使用到了索引,possible_keys 显示可能
possible_keys => 显示可能应用在这张表中的索引,一个或多个,该索引会被列出,但不一定被实际查询使用。
key => 实际应用到本次查询的索引类型。最重要的。如果为NULL,则说明没有使用索引。
MariaDB [lyshark]> explain select col1,col2 from t1;
+——+————-+——-+——-+—————+—————+———+——+——+——-+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+——+————-+——-+——-+—————+—————+———+——+——+——-+
| 1 | SIMPLE | t1 | index | NULL | idx_col1_col2 | 10 | NULL | 1 | |
+——+————-+——-+——-+—————+—————+———+——+——+——-+
——————————————————————————
查询中若使用了覆盖索引,则该索引仅出现key列表中 覆盖索引以下就是原理
MariaDB [lyshark]> create table t1(col1 int,col2 int,col3 int);
MariaDB [lyshark]> alter table t1 add index idx_col1_col2(col1,col2);
— 建立的索引与,查询的行数,必须一致,col1,col2是有索引的。
MariaDB [lyshark]> explain select col1,col2 from t1;
+——+————-+——-+——-+—————+—————+———+——+——+————-+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+——+————-+——-+——-+—————+—————+———+——+——+————-+
| 1 | SIMPLE | t1 | index | NULL | idx_col1_col2 | 10 | NULL | 1 | Using |
+——+————-+——-+——-+—————+—————+———+——+——+————-+
— 扫描三个值,不会出现使用索引的情况。
MariaDB [lyshark]> explain select col1,col2,col3 from t1;
+——+————-+——-+——+—————+——+———+——+——+——-+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+——+————-+——-+——+—————+——+———+——+——+——-+
| 1 | SIMPLE | t1 | ALL | NULL | NULL | NULL | NULL | 1 | |
+——+————-+——-+——+—————+——+———+——+——+——-+
possible_keys,key,ken_len
key_len 表示索引中使用的字节数,这个长度用的越少越好,kenLen长度是根据表的定义计算得出,而不是表中数据检索出的。
ref 显示索引的那一列被使用了,如果可能的话,是一个常数,那些列或常量被用于查找索引列上的值。定义了引用了那些库。
rows 根据表统计信息及索引选用情况,大致估算出找到所需的记录所需要读取的行数,该值当然也是越小越好。 每张表有多少行被优化器查询。
MariaDB [lyshark]> explain select * from lyshark;
+——+————-+———+——+—————+——+———+——+——+——-+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+——+————-+———+——+—————+——+———+——+——+——-+
| 1 | SIMPLE | lyshark | ALL | NULL | NULL | NULL | NULL | 17 | |
+——+————-+———+——+—————+——+———+——+——+——-+
1 row in set (0.00 sec)
MariaDB [lyshark]> create table tt1(id int primary key,col1 varchar(10),col2 varchar(10));
MariaDB [lyshark]> create table tt2(id int primary key,col1 varchar(10),col2 varchar(10));
MariaDB [lyshark]> create index idt_col1_col2 on tt2(col1,col2);
MariaDB [lyshark]> explain select * from tt1,tt2 where tt1.id = tt2.id and tt2.col1 = ‘admin’;
+——+————-+——-+——–+———————–+———+———+—————-+——+————-+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+——+————-+——-+——–+———————–+———+———+—————-+——+————-+
| 1 | SIMPLE | tt1 | ALL | PRIMARY | NULL | NULL | NULL | 1 | |
| 1 | SIMPLE | tt2 | eq_ref | PRIMARY,idt_col1_col2 | PRIMARY | 4 | lyshark.tt1.id | 1 | Using where |
+——+————-+——-+——–+———————–+———+———+—————-+——+————-+
2 rows in set (0.00 sec)
extra 扩展列
using filesort 产生了文件内排序,完蛋了,mysql无法使用索引进行排序,使用了外部的索引排序,而不是按照表内的索引顺序进行读取。mysql无法利用索引完成排序,操作成为文件排序。
MariaDB [lyshark]> create table tab1(id int primary key,col1 int,col2 int,col3 int);
MariaDB [lyshark]> insert into tab1 values(1,1,2,3),(2,4,5,6),(3,7,8,9);
MariaDB [lyshark]> create index tab1_col1_col2_col3 on tab1(col1,col2,col3);
MariaDB [lyshark]> explain select col1 from tab1 where col1 order by col3 \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: tab1
type: index
possible_keys: tab1_col1_col2_col3
key: tab1_col1_col2_col3
key_len: 15
ref: NULL
rows: 3
Extra: Using where; Using index; Using filesort
1 row in set (0.00 sec)
MariaDB [lyshark]> explain select col1 from tab1 where col1 order by col2,col3 \G
查询使用索引,没问题的,只是说,我们没有针对order by 建立排序索引,或者是建立了索引,你没用上!!
以下我们加上全部索引字段,从此下面这条sql性能更高了。
MariaDB [lyshark]> explain select col1 from tab1 where col1 order by col1,col2,col3 \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: tab1
type: index
possible_keys: tab1_col1_col2_col3
key: tab1_col1_col2_col3
key_len: 15
ref: NULL
rows: 3
Extra: Using where; Using index
1 row in set (0.00 sec)
如果可以,尽快优化。
using temporary 彻底完犊子,这个会新建了一个内部临时表,然后操作完后再把临时表删除,动作更凶险。
使用临时表保存中间结果,mysql在对查询结果排序时使用临时表,常用于排序order by 和分组查询group by .
MariaDB [lyshark]> explain select * from tab1 where col1 in(1,2,3) group by col2 \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: tab1
type: index
possible_keys: tab1_col1_col2_col3
key: tab1_col1_col2_col3
key_len: 15
ref: NULL
rows: 3
Extra: Using where; Using index; Using temporary; Using filesort 彻底完犊子
1 row in set (0.00 sec)
解决办法,你给我建立的索引个数和顺序,一定要按顺序来。
MariaDB [lyshark]> explain select * from tab1 where col1 in(1,2,3) group by col1,col2 \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: tab1
type: index
possible_keys: tab1_col1_col2_col3
key: tab1_col1_col2_col3
key_len: 15
ref: NULL
rows: 3
Extra: Using where; Using index 解决了。
1 row in set (0.00 sec)
using index 这种情况是好事,表示相应的操作使用了 covering index 使用了覆盖索引,效率不错,。
如果同时出现了using where 表示索引被用来执行索引键值的查找。
如果没有同时出现using where 表明索引用来读取数据而非执行查找动作。
MariaDB [lyshark]> explain select col1,col2 from tab1;
+——+————-+——-+——-+—————+———————+———+——+——+————-+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+——+————-+——-+——-+—————+———————+———+——+——+————-+
| 1 | SIMPLE | tab1 | index | NULL | tab1_col1_col2_col3 | 15 | NULL | 3 | Using index | using 表明直接从索引上找到了数据。
+——+————-+——-+——-+—————+———————+———+——+——+————-+
1 row in set (0.00 sec)
覆盖索引,就是说你建立的复合索引是 x,y,z 那么你在查询是应该要覆盖这些索引,这样才能让索引,发挥其最大的性能,否则索引等于白建立。
覆盖索引,尽量不要写星号,这种低效率的查询。
select * from lyshark where id=1; — 完蛋的。
select x,y,z from lyshark wehre id =1; — 覆盖到主键上,查询效率提升很多。
using where -> 使用了where using join buffer -> 用到了缓存buffer
实现单表索引优化
create table if not exists article(
id int(10) unsigned not null primary key auto_increment,
author_id int(10) unsigned not null,
category_id int(10) unsigned not null,
views int(10) unsigned not null,
comments int(10) unsigned not null,
title varbinary(255) not null,
content text not null );
insert into article(author_id,category_id,views,comments,title,content) values(1,1,1,1,’1′,’1′),(1,1,1,2,’1′,’1′),(2,2,2,2,’2′,’2′),(3,3,3,3,’3′,’3′);
MariaDB [lyshark]> explain select id,author_id from article where category_id=1 and comments>1 order by views desc limit 1;
— 创建复合索引 all 变为了range 只解决了全表扫描问题
MariaDB [lyshark]> create index idx_article_ccv on article(category_id,comments,views);
— 最后一个完整版的
MariaDB [lyshark]> drop index idx_article_ccv on article;
MariaDB [lyshark]> create index idx_article_cv on article(category_id,views);
实现两表索引优化
create table class
(
id int(10) auto_increment,
card int(10) not null,
primary key(id)
);
create table book
(
bookid int(10) auto_increment,
card int(10) not null,
primary key(bookid)
);
MariaDB [lyshark]> insert into class(card) values(floor(1+(rand()*20))); * 10
MariaDB [lyshark]> insert into book(card) values(floor(1+(rand()*20))); * 10
MariaDB [lyshark]> select * from book inner join class on book.card = class.card;
— 左连接的特性是左表全都有,连接右表的部分
— 左右链接总有一张表是用来驱动的,左连接链接的是右表,如下左表class右表是book
MariaDB [lyshark]> select * from class left join book on book.card = class.card;
— 左连接情况下,将索引建立在右表上面效率是最高的,如下右表是book
MariaDB [lyshark]> alter table book add index left_index(card);
— 右链接,需要将索引加到左边表上,也就是加到class表的card字段上.
MariaDB [lyshark]> show index from book;
MariaDB [lyshark]> drop index left_index on book;
MariaDB [lyshark]> select * from class right join book on book.card = class.card;
MariaDB [lyshark]> alter table class add index right_index(card);
三张表索引优化
create table phone
(
phoneid int(10) auto_increment,
card int(10) not null,
primary key(phoneid)
);
MariaDB [lyshark]> insert into phone(card) values(floor(1+(rand()*20))); * 10
— 最简单的链接查询
MariaDB [lyshark]> select * from class inner join book on class.card=book.card inner join phone on book.card=phone.card;
— 左连接查询
MariaDB [lyshark]> explain select * from class left join book on class.card=book.card left join phone on book.card=phone.card;
alter table book add index book_left_index(card);
alter table phone add index phone_left_index(card);
— join 语句优化建议
— 1. 尽可能减少join语句中的NestedLoop的循环次数: 永远用小结果集,驱动大的结果集.
— 2. 优先优化NestedLoop的内层循环
— 保证join语句中被驱动表上join条件字段已经被索引.
— 当无法保证被驱动表的join条件字段被索引且内存资源充足的前提下,不要太吝惜joinbuffer 的设置.
— 如果是三表,左查询,那么我们应该将索引,建立在左连接表中.
— 右连接查询
MariaDB [lyshark]> explain select * from class right join book on class.card=book.card right join phone on book.card=phone.card;
alter table book add index book_left_index(card);
alter table phone add index phone_left_index(card);
解决中文乱码问题:
[root@localhost mysql]# cp -a /usr/share/mysql/my-huge.cnf /etc/my.cnf
[root@localhost mysql]# vim /etc/my.cnf
[client]
default-character-set=utf8
[mysqld]
character_set_server=utf8
character_set_client=utf8
collation-server=utf8_general_ci
[mysql]
default-character-set=utf8
— 查询字符集编码
MariaDB [lyshark]> select * from information_schema.character_sets;
MariaDB [lyshark]> show character set like ‘utf8%’;
MariaDB [lyshark]> show variables like ‘character_set%’;
— 设置全局字符集
set global character_set_client=utf8;
set global character_set_connection=utf8;
set global character_set_database=utf8;
set global character_set_results=utf8;
set global character_set_server=utf8;
— 更新指定表为utf8格式
MariaDB [lyshark]> alter database lyshark default character set utf8 collate utf8_general_ci;
MariaDB [lyshark]> alter table lyshark.user convert to character set utf8 collate utf8_general_ci;
— 错误日志
[root@localhost ~]# vim /etc/my.cnf
[mysqld]
log-error=”/var/log/mariadb/mariadb.log”
MariaDB [(none)]> show variables like ‘log%’;
[root@localhost ~]# cat /var/log/mariadb/mariadb.log |head -n 10
MariaDB [(none)]> flush logs;
— 二进制日志
[root@localhost ~]# vim /etc/my.cnf
[mysqld]
log-bin=”/tmp” #设置开启日志,也可不指定日志保存位置
expire_logs_days = 10 #设置日志自动清理天数
max_binlog_size = 100M #定义了单个文件的大小限制
— 删除日志
MariaDB [(none)]> show binary logs;
MariaDB [(none)]> purge master logs to “mariadb-bin.000001”;
MariaDB [(none)]> purge master logs before “20180101”;
[root@localhost ~]# mysqlbinlog mariadb-bin.000001
— 慢查询日志
MariaDB [lyshark]> show variables like ‘%slow_query_log%’;
MariaDB [lyshark]> set global slow_query_log=1;
MariaDB [lyshark]> show variables like ‘%long_query_time%’;
MariaDB [lyshark]> set global long_query_time=3;
MariaDB [lyshark]> show global status like ‘%Slow_queries%’;
[root@localhost mysql]# cat /var/lib/mysql/localhost-slow.log
[root@localhost ~]# vim /etc/my.cnf
[mysqld]
log-slow-queries=”/var/lib/mysql/localhost-slow.log”
long_query_time=10
log_output=FILE
-s 排序方式
-c 访问次数
-l 锁定时间
-r 返回记录
-t 查询时间
-al 平均锁定时间
-ar 平均返回记录数
-at 平均查询时间
-t 返回前面多少条记录
-g 匹配正则
— 得到返回记录集最多的10个SQL
[root@localhost mysql]# mysqldumpslow -s -r -t 10 /var/lib/mysql/localhost-slow.log
— 得到访问次数最多的10个SQL
[root@localhost mysql]# mysqldumpslow -s -c -t 10 /var/lib/mysql/localhost-slow.log
— 得到按照时间排序的前十条里面含有左连接的查询语句.
[root@localhost mysql]# mysqldumpslow -s -t -t 10 -g ‘left join’ /var/lib/mysql/localhost-slow.log
show variables like ‘profiling’;
set profiling=on;
MariaDB [lyshark]> select * from tbl_emp;
MariaDB [lyshark]> show profiles; // 查询系统中执行的sql
— 查询3号记录中的问题,得到3号语句的查询生命周期。
MariaDB [lyshark]> show profile cpu,block io for query 3;