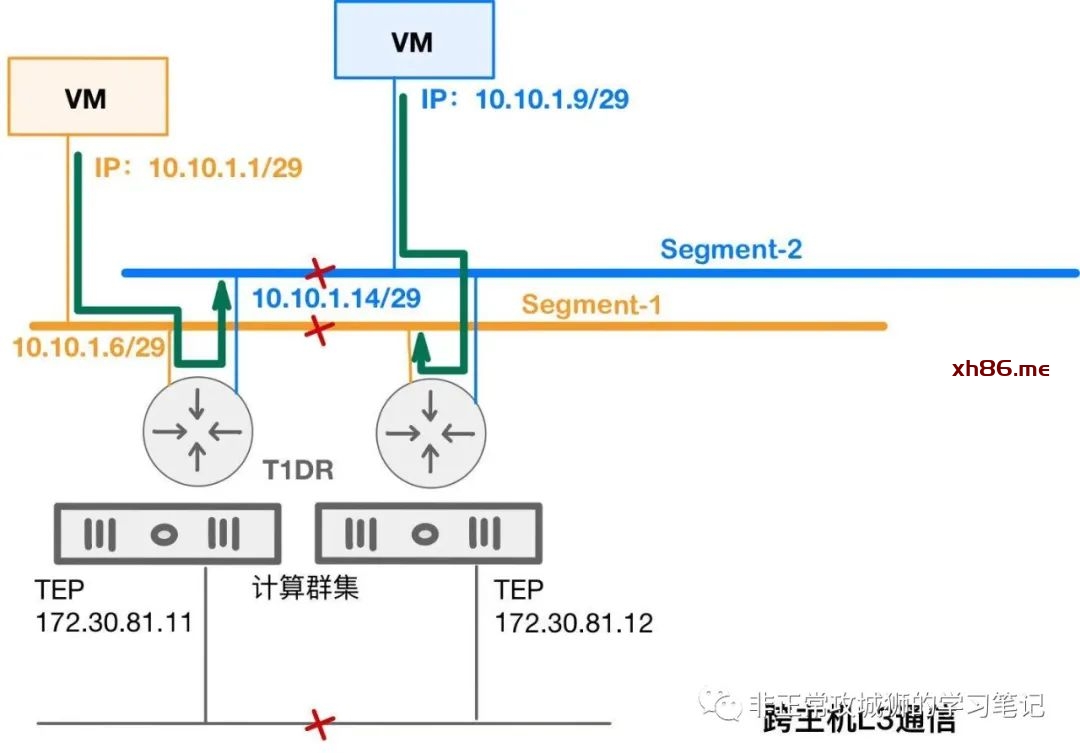
🙀 虚拟机A分配了一个10.10.1.1/28的地址,可以PING通自己的网关10.10.1.6以及另外一个网段的网关10.10.1.14;虚拟机B分配了一个10.10.1.9/28的地址,可以PING通自己的网关10.10.1.14以及另一个网段的网关10.10.1.6;但是虚拟机A和虚拟机B之间在没有任何防火墙策略干预的情况下,无法相互PING通。
造成这样的原因是因为NSX提供路由转发的逻辑路由器是分布式的。通常情况下,在每一台ESXi内核中都会运行一台分布式路由器角色。当虚拟机A尝试与不同网段的网关通信的时候,比如PING 10.10.1.14,实际上是由这台虚拟机所在的ESXi内核中运行的逻辑路由器来响应这个ICMP包;同理,响应虚拟机B ICMP请求的,是虚拟机B所在的ESXi内核中运行的逻辑路由器。因此,上述问题的故障点既然不出在逻辑链路上,基本可判断是Underlay出现了问题,比如MTU未正确配置,TEP之间三层通信故障等。
因此,无论是学习还是实践,想要真正玩转NSX的逻辑网络,各位首先要理清楚在不同NSX模型中,逻辑路由器实例的分布状态。
|
所有分段全部
连接到T0网关
|
所有分段连接到T1网关
T0网关承载服务
|
所有分段连接到T1网关
T1网关承载服务
|
|
主机传输节点中
逻辑路由器实例
|
T0分布式路由器角色 |
T1分布式路由器角色
T0分布式路由器角
|
T1分布式路由器角色 |
|
边界传输节点中
逻辑路由器实例
|
T0分布式路由器角色
T0服务路由器角色
|
T1分布式路由器角色
T0分布式路由器角色
T0服务路由器角色
|
T1分布式路由器角色
T1服务路由器角色
T0分布式路由器角色
T0服务路由器角色
|
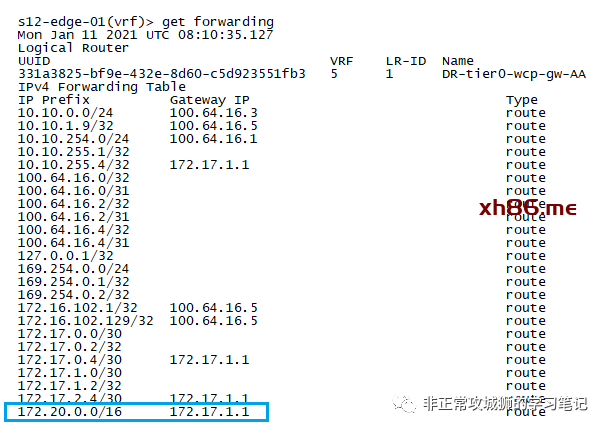
由此可见,主机传输节点只会存在分布式路由器角色,而服务路由器角色只会存在于边界传输节点。管理员访问承载业务的某一台主机传输节点,通过命令行可以查看内核中运行的逻辑路由器实例:
从输出上不难看出,这些都是【VDR】,也就是虚拟分布式路由器的简称。
将UUID与NSX Manager管理器的输出进行对比,可以明确UUID尾号是【d1af】、【9d49】、【b538】的路由器实例分别是【DR-tier1-global-dw-direct】、【DR-tier1-tenant1-gw-nat】、【DR-tier1-dvwa-gw-direct】,均为Tier1逻辑路由器的分布式路由器角色。
🐂【干货2】NSX逻辑网络,一言以蔽之,曰“先路由后转发”
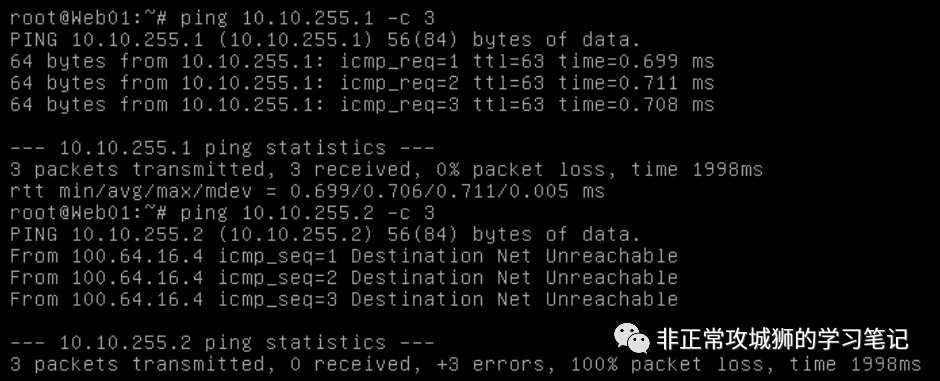
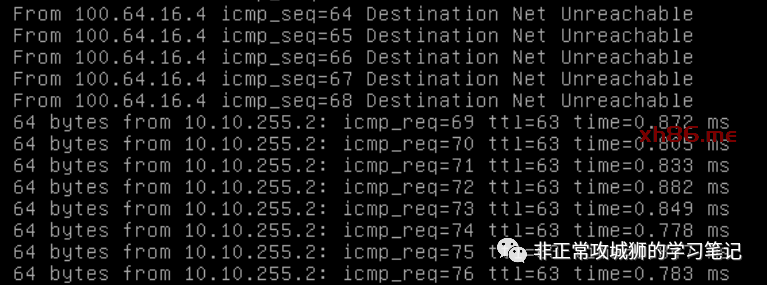
接下来,我们不妨来看看10.10.1.1虚拟机与10.10.1.9虚拟机在相互通信的时候,数据流是如何进行的。在学习和实践NSX的时候,必须要对NSX【先路由后转发】的要义烂熟于胸,这样处理故障排查的时候,才能得心应手。
当10.10.1.1尝试与10.10.1.9通信的时候,数据包的转发路径是这样的(红色箭头方向)
❶> 10.10.1.1/29发现目的地址10.10.1.9/29并非自己L2网络,将其发往自己的网关,即10.10.1.6/29。
❷> 10.10.1.1/29所在的ESXi主机内核中的逻辑路由器T1DR收到了这个包,查阅自己的路由表信息;目的地址是自己的直连网络,将发往10.10.1.14/29这个接口。
❸> 由于10.10.1.14/29是该ESXi主机内核中逻辑路由器T1DR的这个接口,因此这个数据包目前仍然在该ESXi内核中“行走”,并没有到达Underlay网络。
✂==============================
===============================
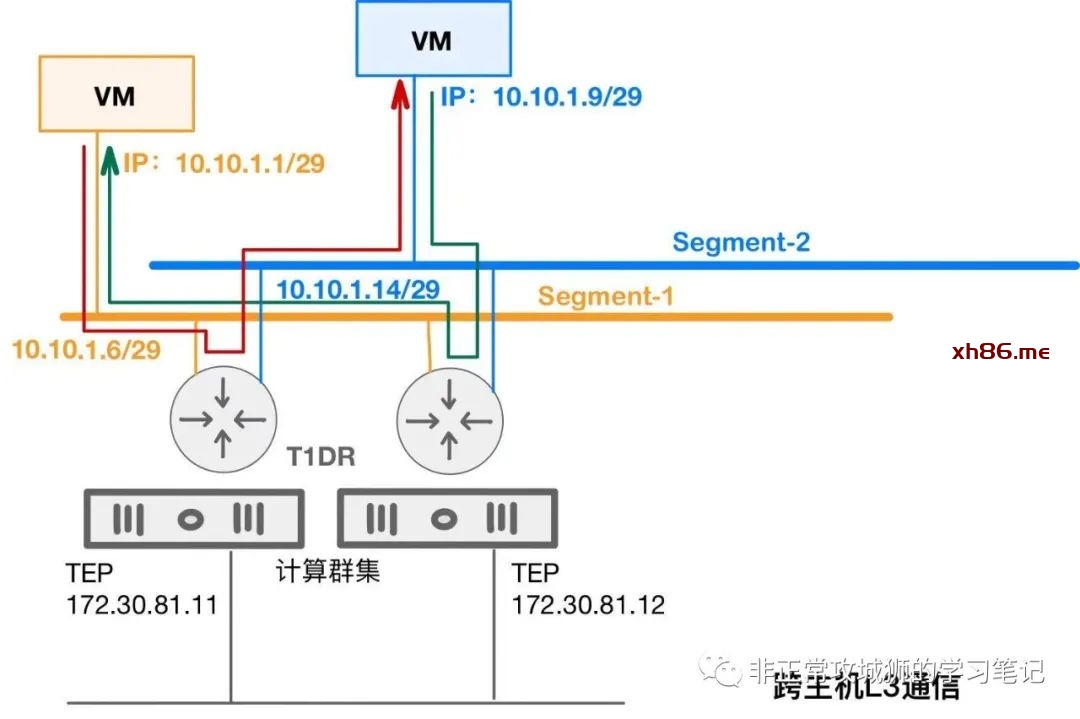
❹> 因为目的地址是10.10.1.9/29,对于10.10.1.14/29网关来说,这是自己直连网段上的一个IP地址,将依次触发ARP表查询、MAC表查询、VTEP表查询等一系列控制平面的流程。最终的结果是TEP IP为172.30.81.11这台主机了解到目的位于172.30.81.12这台主机。
❺> 172.30.81.11的TEP将该数据包进行封装,通过Underlay网络转发到172.30.81.12这个TEP。
➏> 172.30.81.12的TEP收到了这个数据包,进行解封装,然后通过Segment-2逻辑网络,发往目的虚拟机。
以上是数据包从10.10.1.1到10.10.1.9的路程;但回包的路程并非是“怎么来,怎么回”而是由于NSX的【先路由后转发】,出现了“路径不一致”的特殊情况。这是工程师在进行NSX项目实施和排障的时候,必须要明确的。那10.10.1.9回包10.10.1.1的路径究竟是怎么样的呢?
|
S 10.10.1.1->D 10.10.1.9
|
S 10.10.1.9->D 10.10.1.1
|
S1
|
10.10.1.1->10.10.1.6
|
10.10.1.9->10.10.1.14
|
S2
|
10.10.1.6->10.10.1.14
|
10.10.1.14->10.10.1.6 |
S3
|
10.10.1.14->10.10.1.9
|
10.10.1.6->10.10.1.1
|
S4
|
封装:172.30.81.11->172.30.81.12
|
封装:172.30.81.12->172.30.81.11
|
S5
|
Underlay传输
|
Underlay传输
|
S6
|
解封装:到达10.10.1.9
|
解封装:到达10.10.1.1
|
不难看出,两台虚拟机进行通信的时候,往返的路径是不一致的。最明显的就是“去程”的10.10.1.0/29到10.10.1.8/29之间的三层路由是由 TEP地址为172.30.81.11的主机内核中的逻辑路由器实现的,而“返程”则是由172.30.81.12主机内核中的逻辑路由器实现的。
突发感慨经常有人说,NSX很难,是一门易学难精的学问。对于这种说法,晓冬不置可否。但如果过分用传统网络的思想来学习NSX,的确会可能到处碰壁。
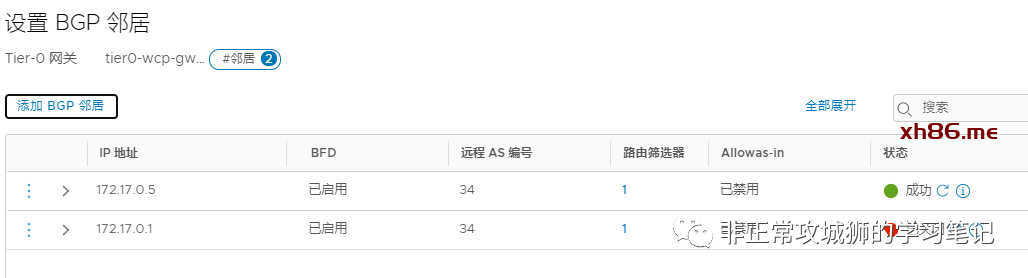
有不少粉丝问我关于“Inter-SR iBGP”这个新功能的一些问题。在NSX管理的界面上,它仅是一个“Enable/Disable”的配置项;但这个选项背后是一连串NSX底层原理的支撑。这个功能适用于什么场景?这个功能应该怎么样来用?想要回答清楚这些问题,首先要搞清楚几个其他的问题。
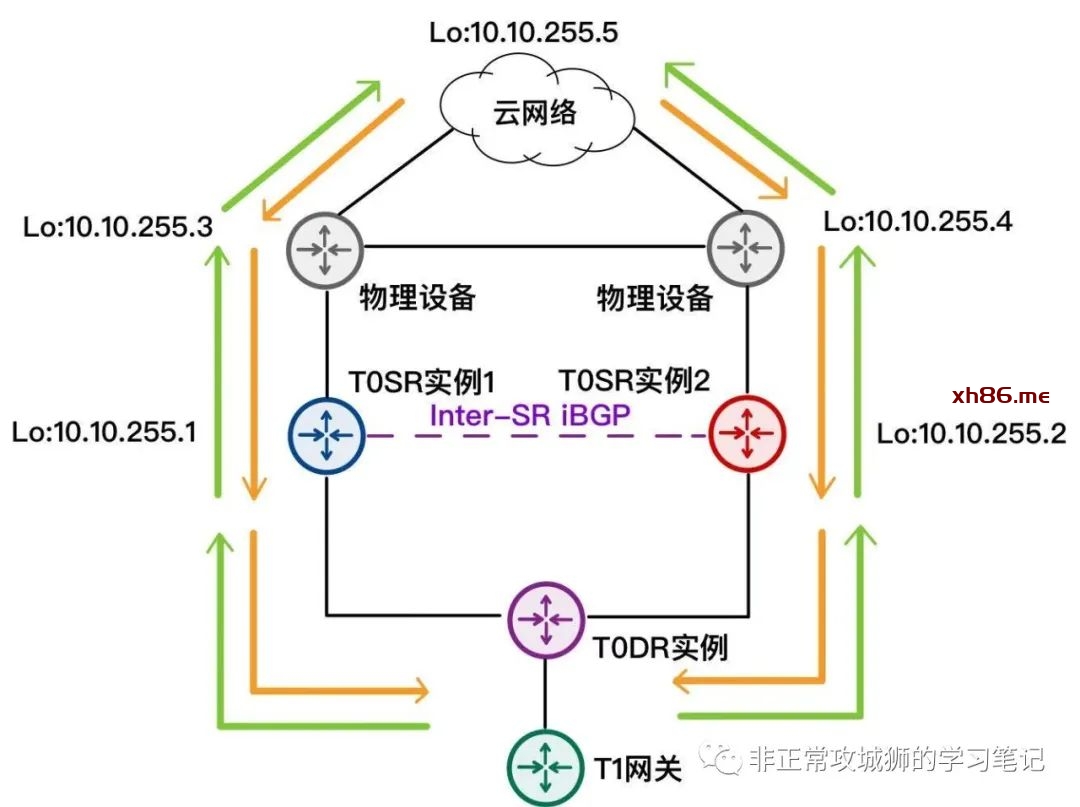
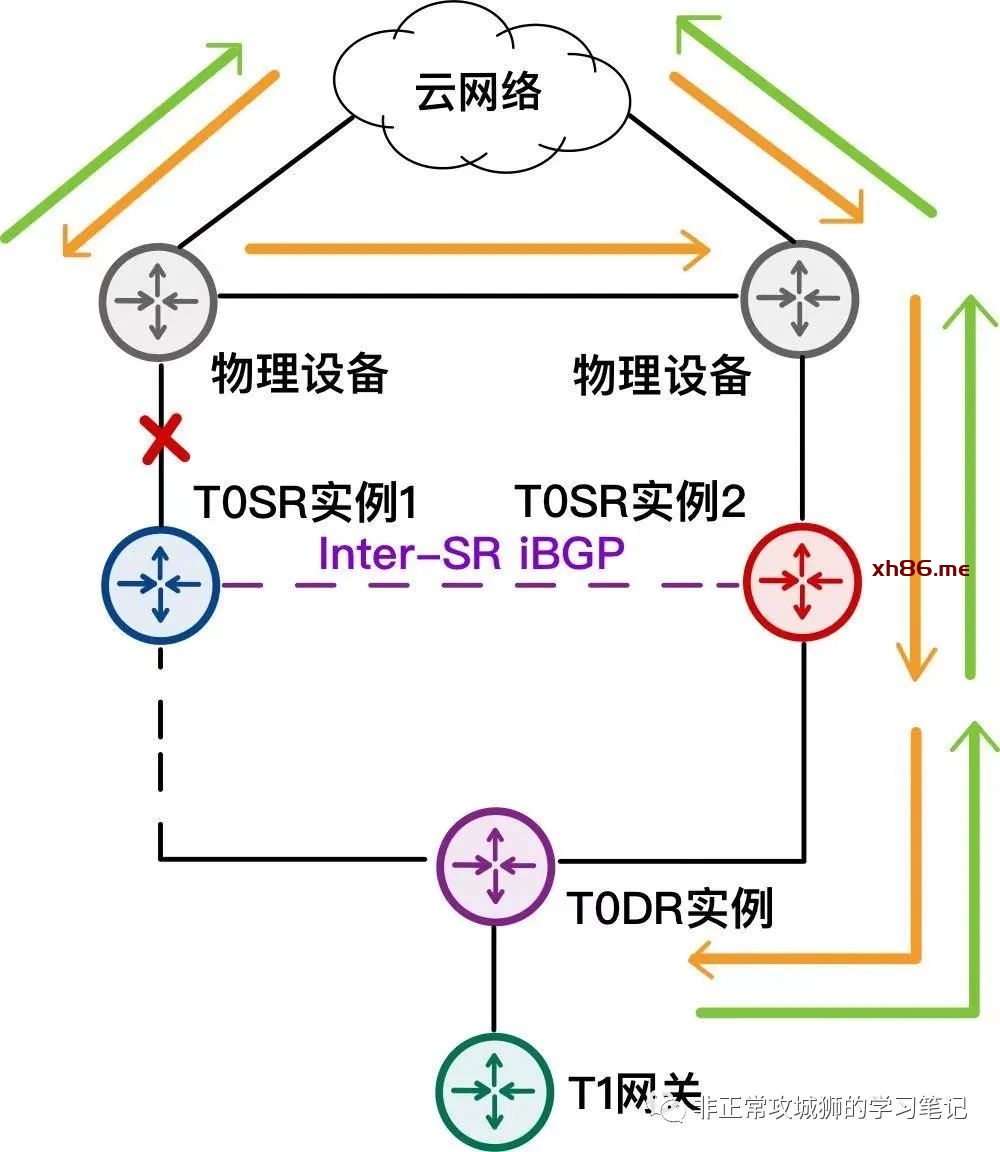
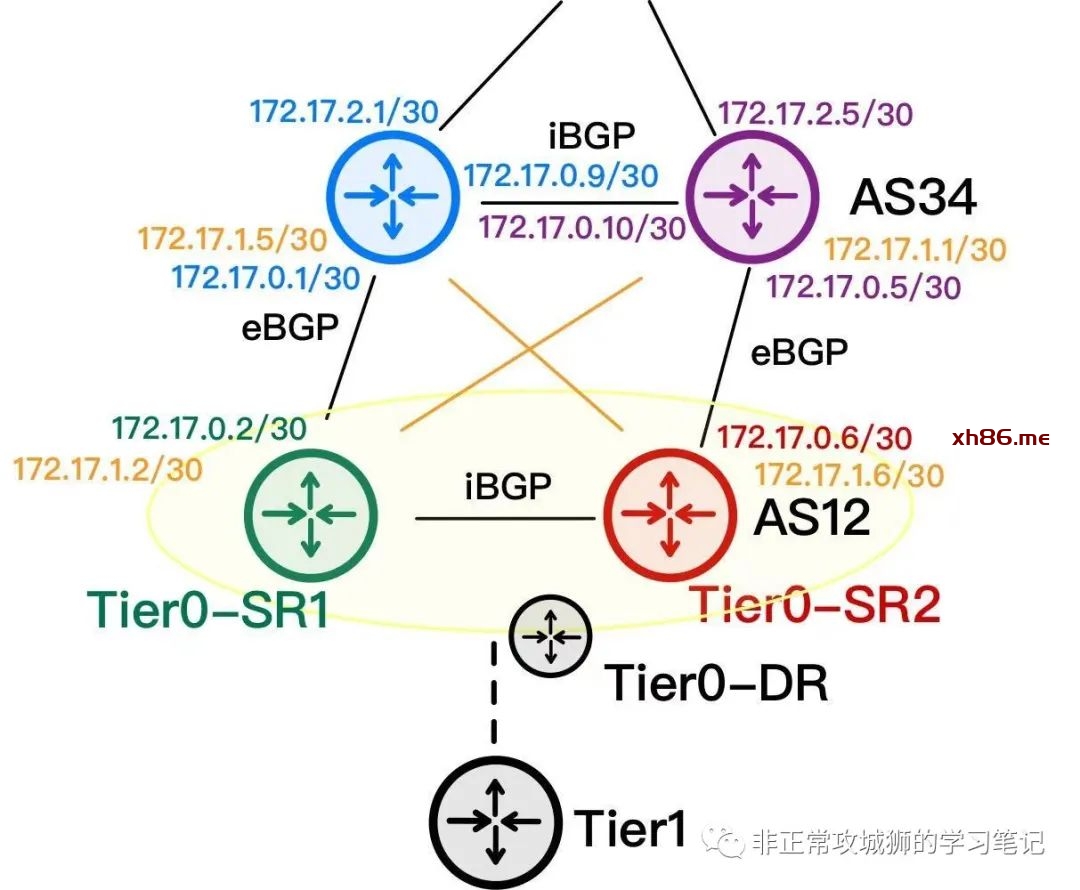
比如:AA模式下Tier0网关的冗余实现原理。如下图所示,这是一个典型的NSX网络拓扑:
一般情况下,T0网关采用Active-Active的方式部署;有一些用户,设计T0网关采用静态路由+BFD的方式与上游物理设备实现【逻辑–物理网络互通】;而另一部分用户,会设计T0网关采用eBGP+BFD的方式与上游物理设备建立BGP邻居,通过动态路由协议实现互通。但无论哪两种情况,均不影响AA模式的冗余生效。
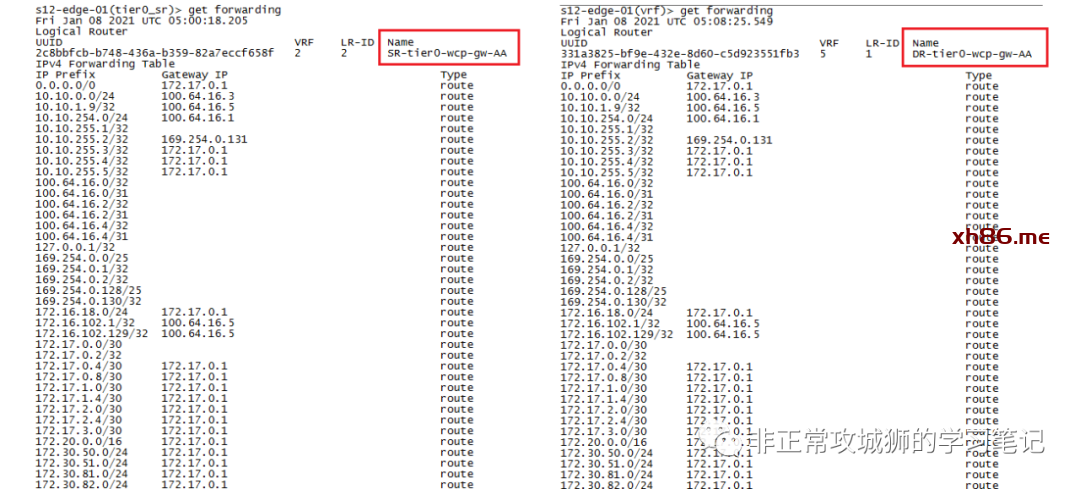
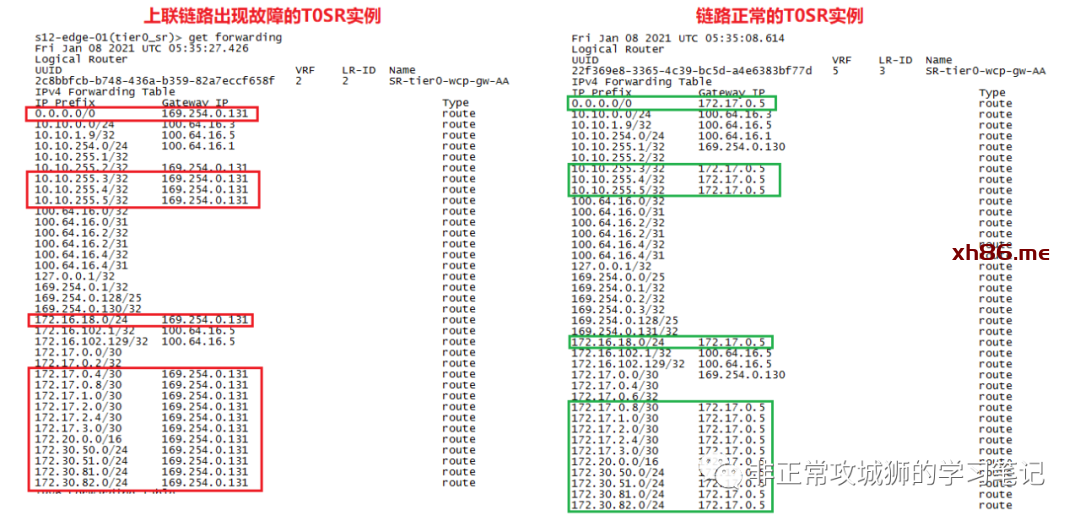
现在,我们将目光聚焦在T0DR实例与两台T0SR实例:
首先是两台T0SR实例,都通过各自的eBGP协议学习到了包括默认路由在内的物理网络路由;值得注意的是,在启用了Inter-SR iBGP链路的情况下,T0SR会学习到对端SR的环回地址路由。
【重点:此时还无法看出AA模式是如何实现冗余的,也无法明确Inter-SR能实现什么功能。】
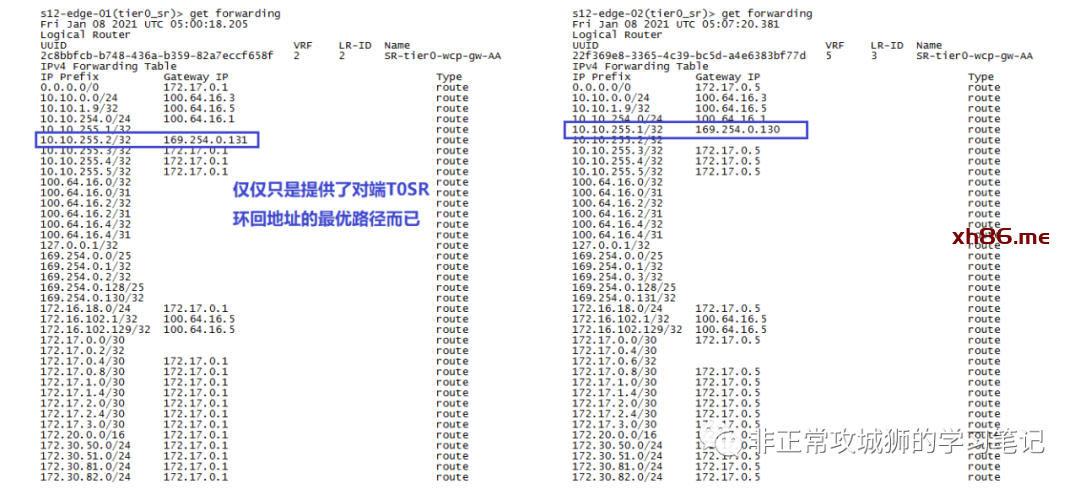
查阅两台T0SR的转发表,在正常情况下,Inter-SR iBGP实现的功能似乎只是“让NSX逻辑网络在访问T0SR环回地址的时候,可以有最优路径而已”。
再来看看T0DR的转发表,不难看出:在正常情况下,同一台Edge实例中的T0DR的转发表与T0SR完全相同。
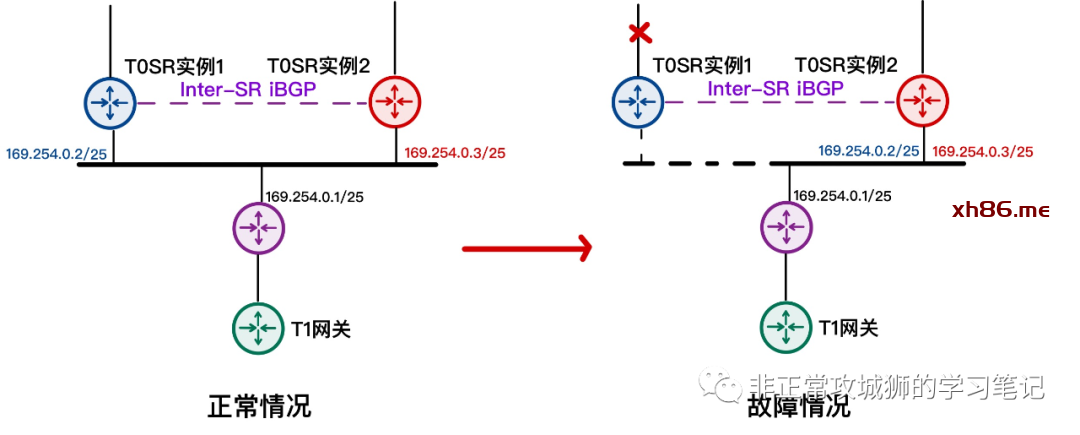
接下来,我们断开T0SR-1实例与上游路由器之间的链路,造成eBGP邻居中断:
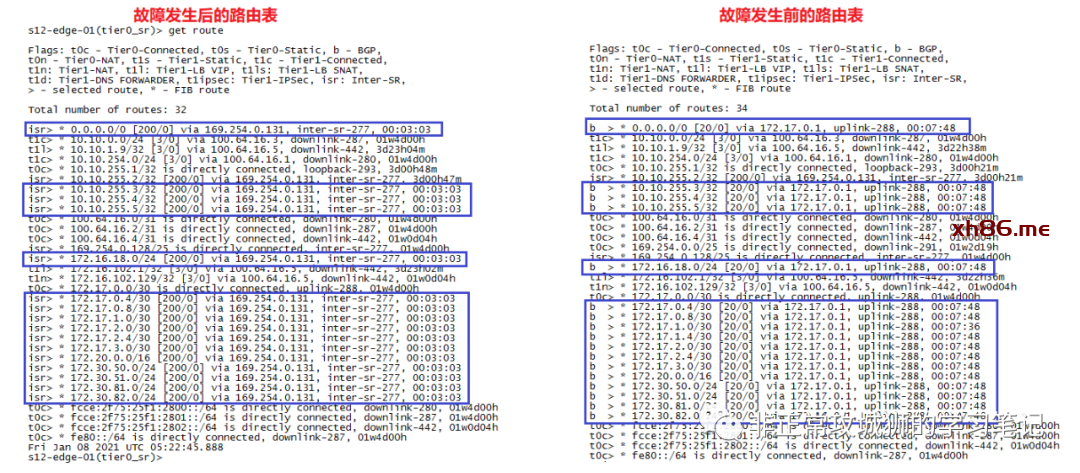
这个时候T0SR-1实例的路由表发生了巨大的变化:
通过对比不难看出,原先包括静态路由在内的所有路由出口,都从与上游路由器互联的故障接口,转而通过Inter-SR iBGP链路,发往另外一台T0SR实例。
查看两台故障发生后T0SR实例的转发表,可以清楚地了解这些变化。
到这里,相信各位一定会产生一个直观的想法【Inter-SR iBGP能够在T0SR出现不对称故障的时候,将T0DR转发过来的流量,通过iBGP链路,发往其他正常T0SR,实现业务冗余性】。
似乎这种说法并没有什么不对的地方,很符合到此为止我们看到的NSX的变化,但真实的情况果真如此么?
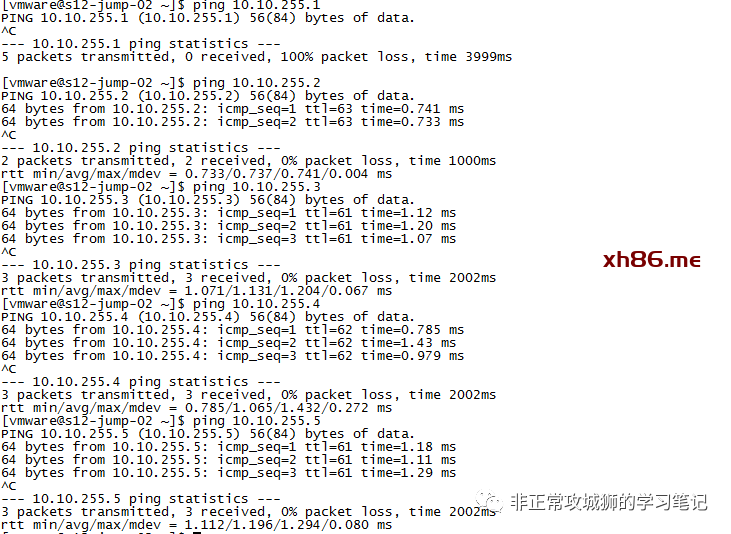
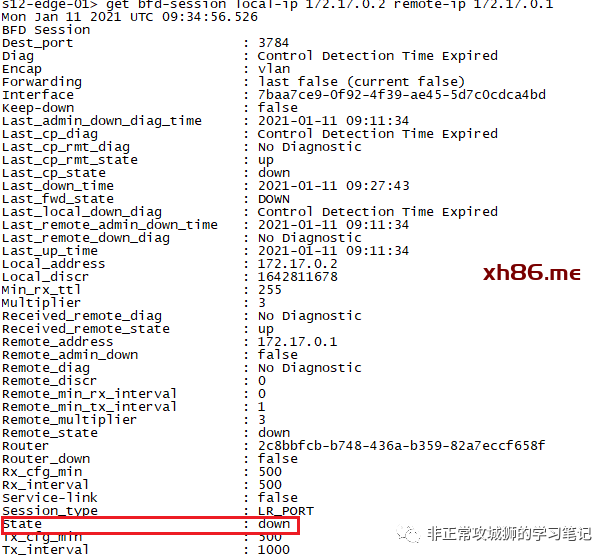
可以看到,我的一台NSX逻辑网络的虚拟机,尝试PING T0SR-1环回地址的时候,显示并不可达!
这就推翻了上文的观点。因为按照上文的说法,在T0SR上行链路出现故障的时候,iBGP链路会代替上行链路进行转发(转发到其他正常T0SR进出);这个时候其实出现上行链路故障的T0SR实际是有流量的,至少下游的NSX T1网络可以正常访问到这台T0SR实例(比如环回地址)。
可通过PING包,不难看出,T0SR-1实例其实并不可达,所有到T0SR-1上联路由器(10.10.255.3)的流量,全部经过T0DR到T0SR-2之间的链路,而不是通过T0DR-T0SR-1-iBGP链路-T0SR-2这样的路径。
所以,想要真正理解Inter-SR iBGP功能的真实用途,一定要对NSX T0SR AA冗余模式的底层原理有深入的了解作为前提。
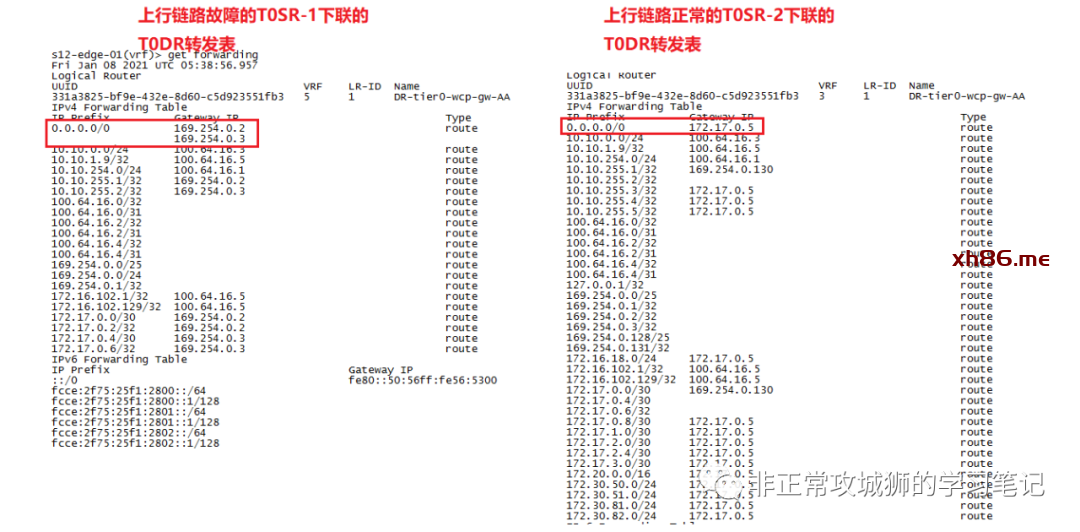
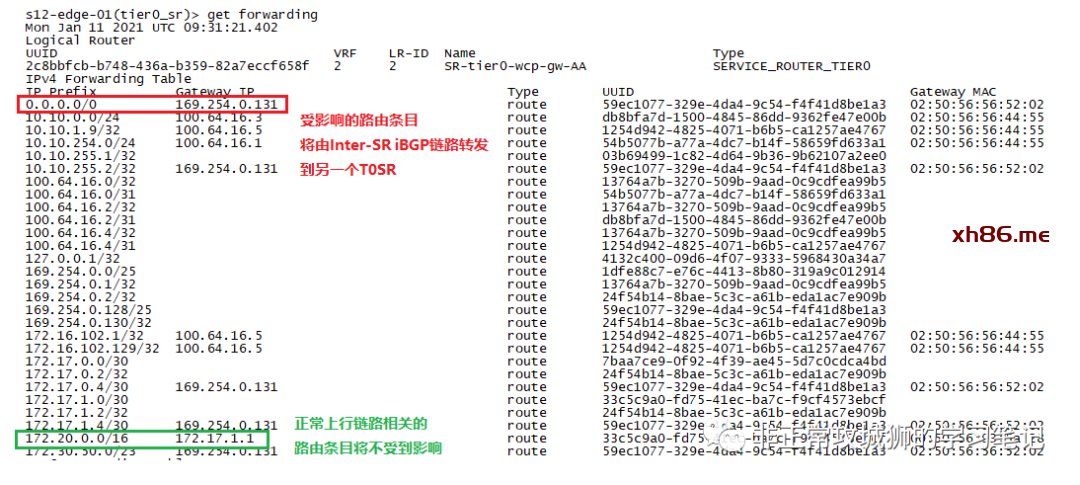
➀. 少了通过eBGP学习到的路由条目,比如172.30.81.0/24;
➁. 保留了T0SR-1直连网络的路由条目,比如172.17.0.0/30(172.17.0.2/32)
➂. 最重要的是0.0.0.0/0默认路由的下一跳地址发生了根本的改变
故障发生后,所有到物理网络的路由,全部由T0DR转发到169.254.0.2和169.254.0.3这两个下一跳IP地址;
了解NSX原理的同事一定知道,169.254.0.0/24的地址段是用于T0DR和T0SR以及T1DR和T1SR之间的内部互联使用的;由此可预见169.254.0.2和169.254.0.3是T0SR的下联地址。
换言之,当T0SR-1出现故障后,所有到达这台Edge传输节点的T0DR的流量(T1SR正好由这台Edge传输节点承载的NSX内部网络南北向的流量)会由这台T0DR实例转发到169.254.0.2和169.254.0.3。
与此同时,另外一台Edge节点内核中的T0DR转发表不变。
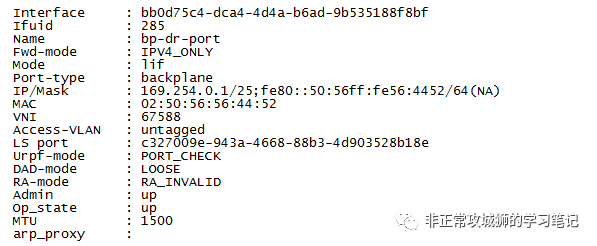
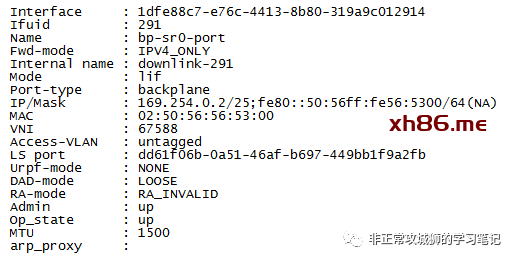
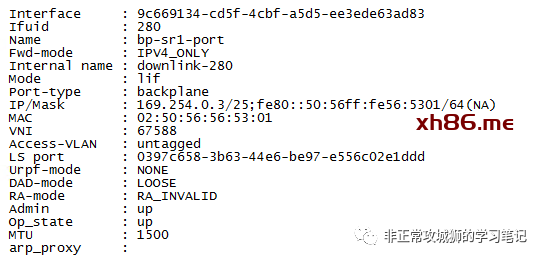
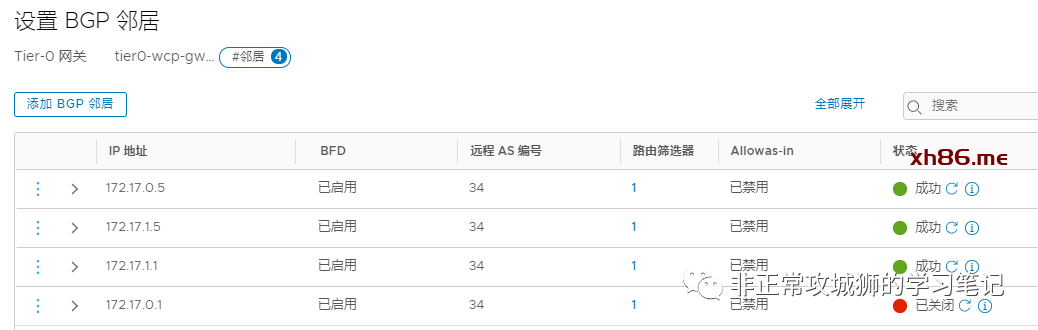
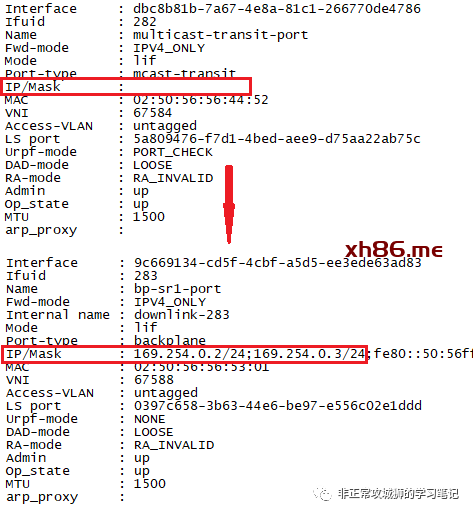
那么,169.254.0.2和169.254.0.3是否如我们所预见,是T0SR的下联接口呢?通过命令行可以找到以下信息:
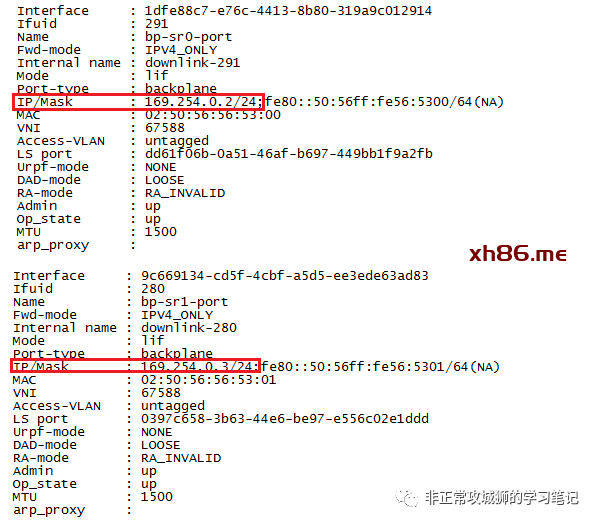
169.254.0.1/25是Tier0DR的上联BP接口(Backplane-DR-Port),
169.254.0.2/25是T0SR-1实例下联T0DR的接口地址,
169.254.0.3/25是T0SR-2实例下联T0DR的接口地址,
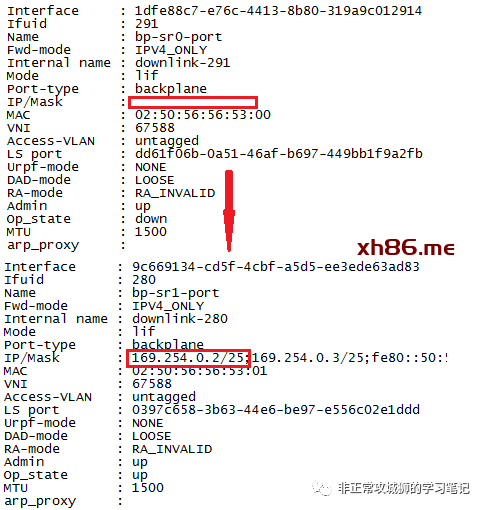
当故障发生后,169.254.0.2/25这个地址会“漂移”到T0SR-2实例上,这是AA模式下T0SR高可用实现的核心原理。
由此可见,AA模式下,当T0SR仅有一根上行链路的时候,如果这条上行链路出现故障,eBGP邻居丢失的情况下,T0DR不再将流量发往这台T0SR实例(如T0SR-1)。换言之,T0SR-1不再有任何的南北向流量,因此在这种情况下Inter-SR iBGP链路并没有任何实质性的意义。在T0网关配置页面,管理员此时Enable/Disable Inter-SR iBGP其实并不会对T0网关的南北向高可用性产生任何有利或者不利的影响。
不过,通过上述用例,我们至少明确了【AA冗余模式下,T0网关的高可用原理】。现在来解释一下,为什么内部网络无法PING通10.10.255.1这个T0SR-1的环回地址:
数据包从内部网络经过T1DR-T1SR(活动的)-T0DR的转发后,下一跳一定是转发到T0SR-2实例。如果没有Inter-SR iBGP链路,那么自然不会有进一步的转发(因为无论是上游物理设备还是T0SR-2都无法通过BGP学习到10.10.255.10这个地址);如果有Inter-SR iBGP,那么流量的确会被转发到T0SR-1。但是由于T0SR-1的转发表中,NSX下联网络全部会发往100.64.0.0/16,也就是必须经过T0DR才能到达的T1SR,由于T0SR-1和T0DR之间已经没有互联的链路,所以数据包将不在被转发,这就导致了内部网络无法PING通10.10.255.1这个IP地址的情况。
接下来,我们再回过头来看“Inter-SR究竟应该怎么用?”这个问题。
🐂【干货4】Inter-SR iBGP实现原理
既然T0SR的每一台实例在单链路上联的场景下,是否启用Inter-SR iBGP没有任何实质性的作用;那我们不妨为每一台实例配置至少两条链路上联,再来分析Inter-SR iBGP的影响。
区别于之前的拓扑,每一台T0SR都有2根上行链路,组成了“|X|型”的网络互联拓扑。
我们在启用Inter-SR iBGP功能的情况下,中断T0SR-1实例的其中一条上行链路,造成172.17.0.2/30与上游路由器172.17.0.1/30之间的通信中断,eBGP邻居丢失。
对于业务来说,最明显的“改良”就是NSX网络可以在T0SR-1中断一条上行链路的情况下,依旧可以正常访问T0SR-1的环回地址。
因此,Inter-SR iBGP的适用场景是单独的T0SR实例拥有多条上行链路的情况。同时,我们不妨再多做几个Trace Route测试。
注:这里会用到【逻辑路由器角色分布】和【先路由后转发】的知识点。
我们可以分别选取T1SR与故障的T0SR-1实例位于相同/不同Edge节点的NSX网络来进行测试。
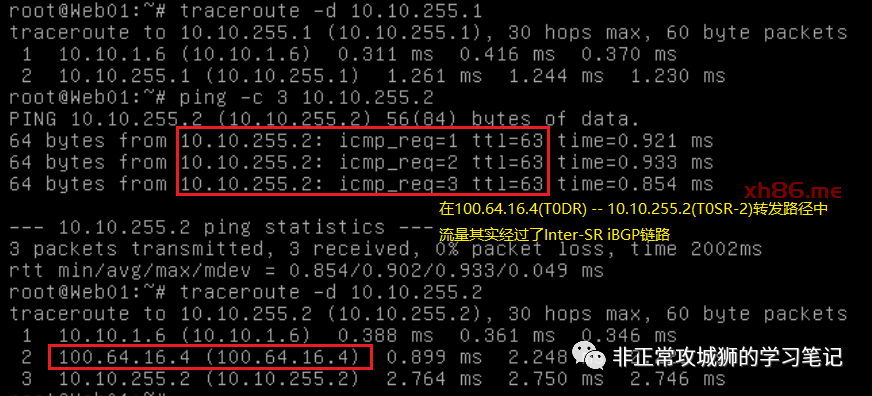
对于T1SR(活动的)和T0SR-1位于相同Edge传输节点的业务虚拟机来说,访问T0SR-2环回口的流量路径是{T1DR->T1SR}->{T0DR->T0SR-1}–Inter-SR iBGP链路–>{T0SR-2},物理跃点计数为2;
对于T1SR(活动的)与T0SR-1位于不同Edge传输节点的业务虚拟机来说,访问T0SR-2环回口的流量路径是{T1DR->T1SR}->{T0DR->T0SR-2},物理跃点计数为1。
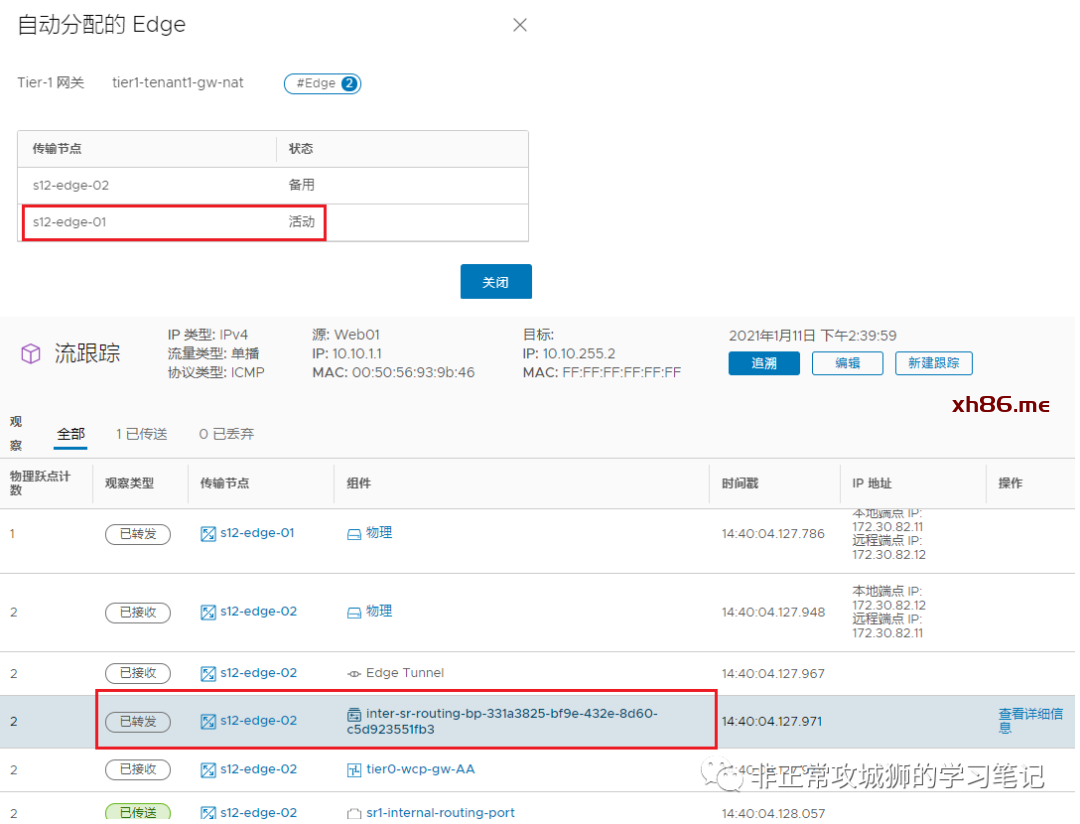
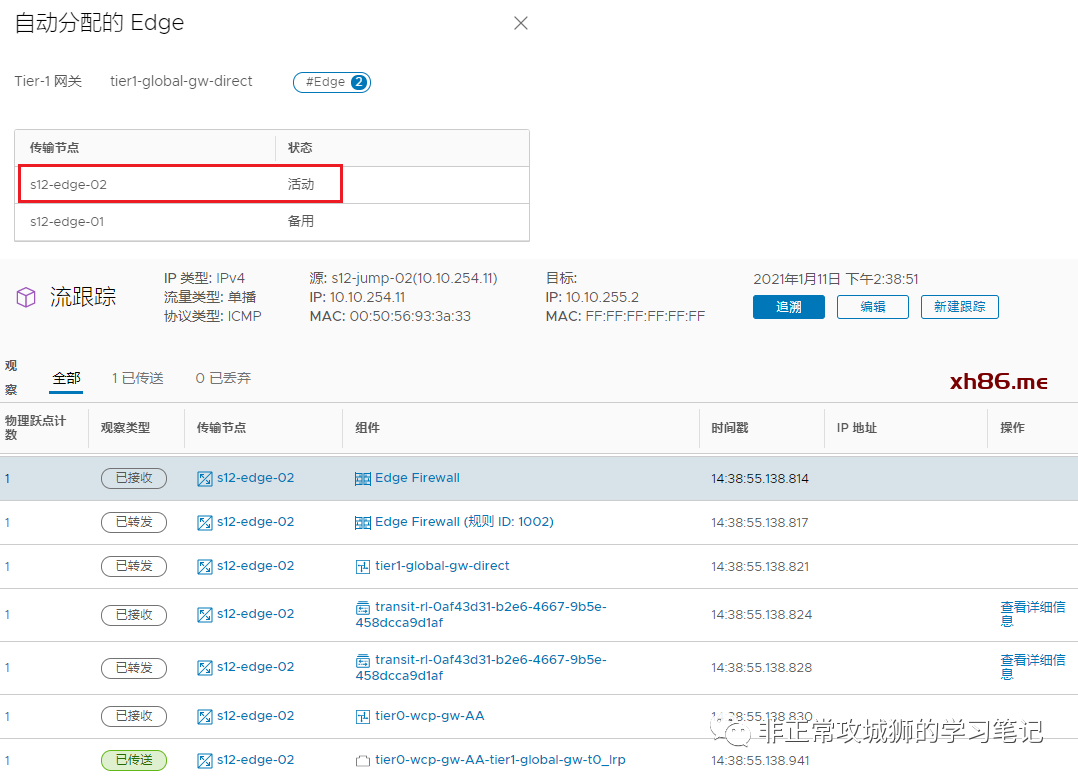
虽然通过NSX的TraceFlow工具,可以清晰地看到流量经过了Inter-SR iBGP链路转发。
但是从命令行来看,TTL=63并非62;这说明Inter-SR iBGP这条链路具有一条隐含的属性【流量经过Inter-SR iBGP链路的时候,TTL不减少】。这对于NSX项目的故障诊断是非常重要的一条原理。
有人说,“如果只是能够PING通环回口,其实没多大意义啊。”
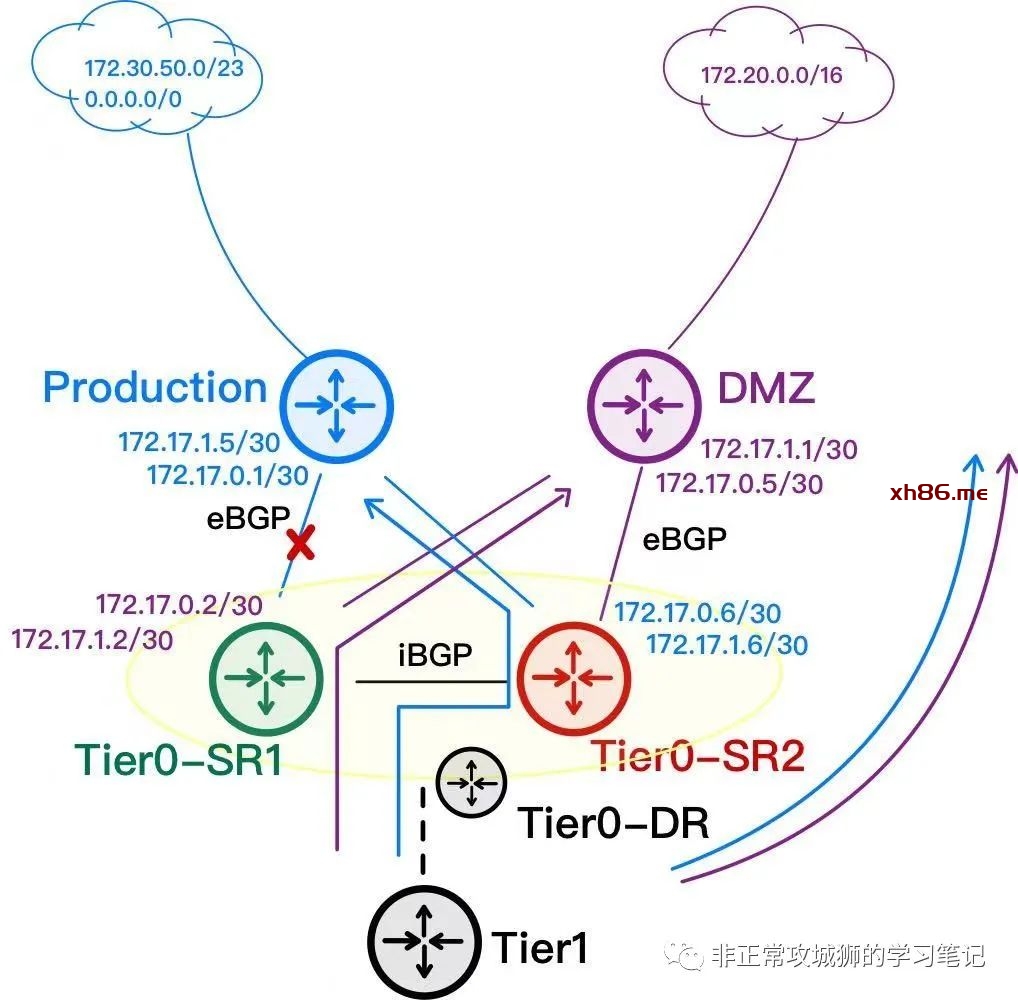
的确,在当前呈现的网络环境下,Inter-SR iBGP的确如此。因为同一个T0SR实例的不同上联其实只承载了“相同区域”的业务而已。那如果T0SR实例的不同上联承载了“不同区域”的业务呢?比如每一台T0SR实例的上行链路1是Production网络(默认路由会走这根上行链路),上行链路2是DMZ网络呢?
在开启Inter-SR iBGP链路的情况下,对于到达Tier0-SR的流量来说:
如果Production区域的,由于上行链路故障,会通过Inter-SR iBGP链路经过T0SR-2的上行链路进行转发,满足在T0SR出现不对称故障的时候,业务的高可用性;
如果是DMZ区域的,由于上行链路状态正常,依旧会通过T0SR-1进行转发。
这一点通过查看T0SR实例的转发表或者路由表加以验证。
换言之,这种【同一个T0SR实例,会承载多个不同区域业务的场景下,Inter-SR iBGP功能是必须要开启的】!
那如果不开启Inter-SR iBGP在这种场景下会造成哪些“重大影响呢”?首先来看关注一下如果取消了Inter-SR iBGP,Intra-T0的接口IP是否会发生漂移。
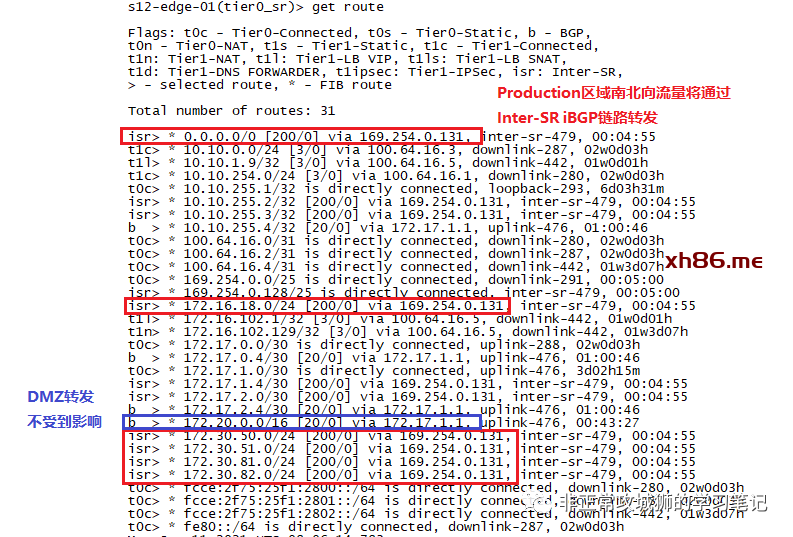
区别于同一个T0SR只有一根上行链路的情况,在多条上行链路的场景下,169.254.0.2这个地址并没有发生漂移的情况。这就说明,对于T0DR来说,它会将北向流量持续的发往T0SR-1或者T0SR-2实例。
查看T0SR-1所在的Edge传输节点内核中的T0DR转发表:
由于T0SR-1与Production互联的网络出现了中断,造成eBGP邻居丢失,因此学习不到包括默认路由在内的所有Production路由(如172.30.50.0/24)。(甚至连T0SR-2的环回地址都学习不到了)于是业务中断将不可避免。
而此时如果所有T0SR-1上行链路均出现中断或者承载T0SR-1的Edge节点出现了故障,业务将会“恢复”。
这不是因为Inter-SR iBGP的缘故,而是169.254.0.2出现了漂移,所有的南北向流量不再经过T0SR-1,而是全部经过T0SR-2了。这是【干货3】的知识点哦!
最后,来简单总结一下【干货4】:Inter-SR iBGP提供了同一个T0SR实例拥有多根上行链路场景下,出现不对称故障时,南北向流量的高可用性;最常用的场景是多根上行链路承载了不同业务/区域的流量。
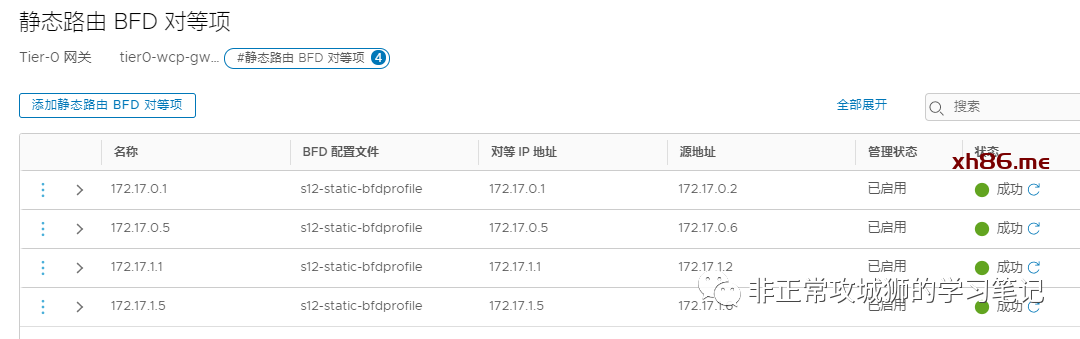
那么,静态路由的场景下,Inter-SR iBGP有它激活的意义么?
当172.17.0.1与172.17.0.2之间的链路出现了故障,那么对应的静态路由转发的流量,会通过Inter-SR iBGP链路,转发到另一台T0SR实例进行北向转发。
看到这里,相信各位也明白了一点。其实晓冬今天真正想要分享的是【Inter-SR iBGP链路能提供哪些功能?】之前的三个Tips都是为了说清楚这个原理而做的铺垫。由此也可见,对于NSX的学习需要有系统的认知,也同样需要实践去验证和加深掌握。