模型定义
本篇的标题是“为什么需要NSX-T Federation?”对于Federation的使用场景,相信朋友们都通过VMware的官网、公众号和其他途径的宣传有所了解了。因此,本篇分享中笔者只想从“纯技术”层面,来说说自己对于Federation,以及与之前的NSX跨站点部署模型异同点的理解。
为了便于后文的说明和理解,笔者先来给几种NSX跨数据中心的部署模型来一个标识定义。
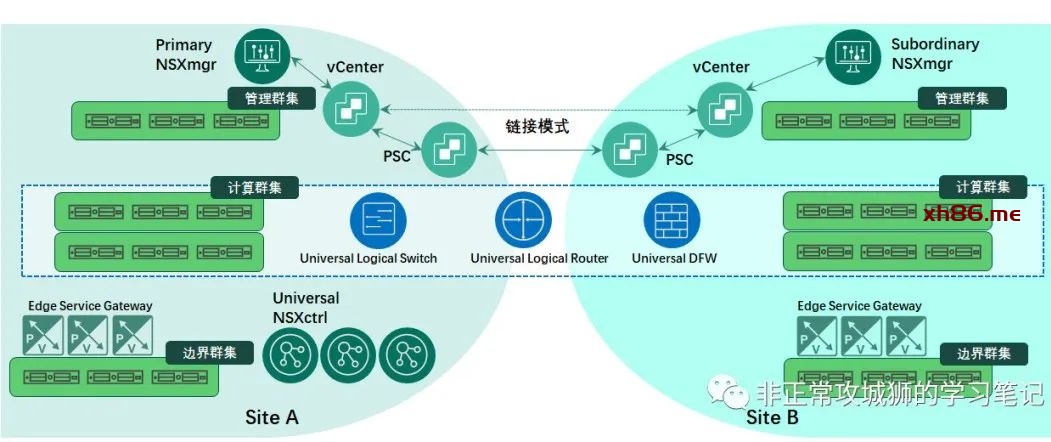
🔆01×01.V模型:NSX for vSphere(早些版本的NSX-V)Cross Site
虽然NSX-V即将成为历史,但V模型还是有值得讨论的地方。在V模型中,每个数据中心均有vCenter与NSXmgr保持着1:1的对应关系,vCenter之间通过链接模式“相互可见”,多个数据中心中,只有一台NSXmgr是Primary服务器(V模型的NSXmgr没有多实例集群的冗余架构),其他NSXmgr均为Subordinary服务器。真正能够接受管理员通过UI或者API配置的,只有角色为Primary的NSXmgr。V模型中的控制器NSXctrl总共只有三台,作为全部数据中心的控制平面。
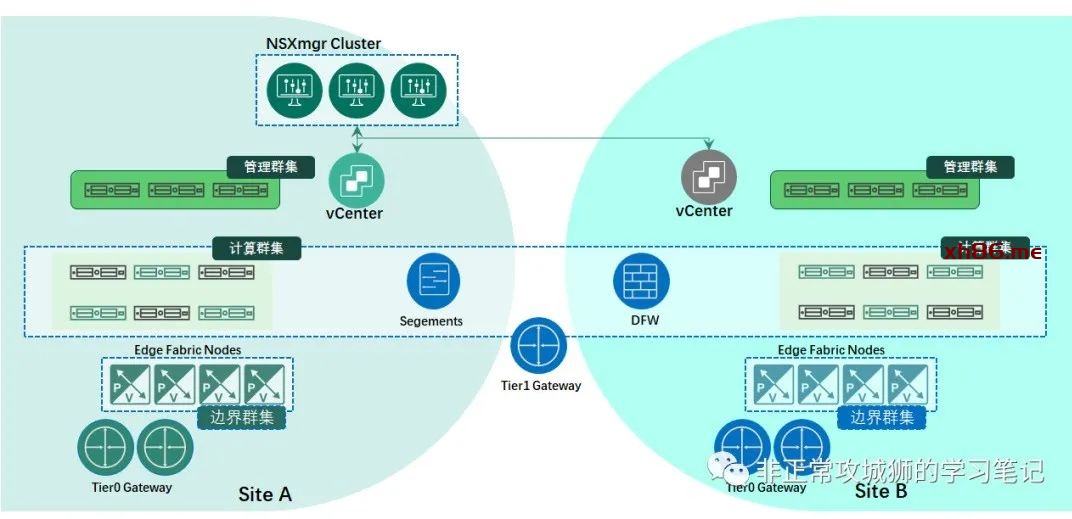
🔆01×02.T模型:NSX-T Multi-Site
NSX-T在Federation之前也有跨数据中心的多站点架构。但与V模型不同的是,NSX-T与vCenter不再具有强制的1:1的注册关系,多个数据中心的vCenter可以作为计算管理器注册到同一台NSXmgr。在NSX-T的某个版本之后(笔者所记不差应该是2.4~~),NSXmgr与NSXctrl合并,因此现在的架构是三台NSXmgr组成一个集群,作为多个数据中心的集中管理与控制平面。
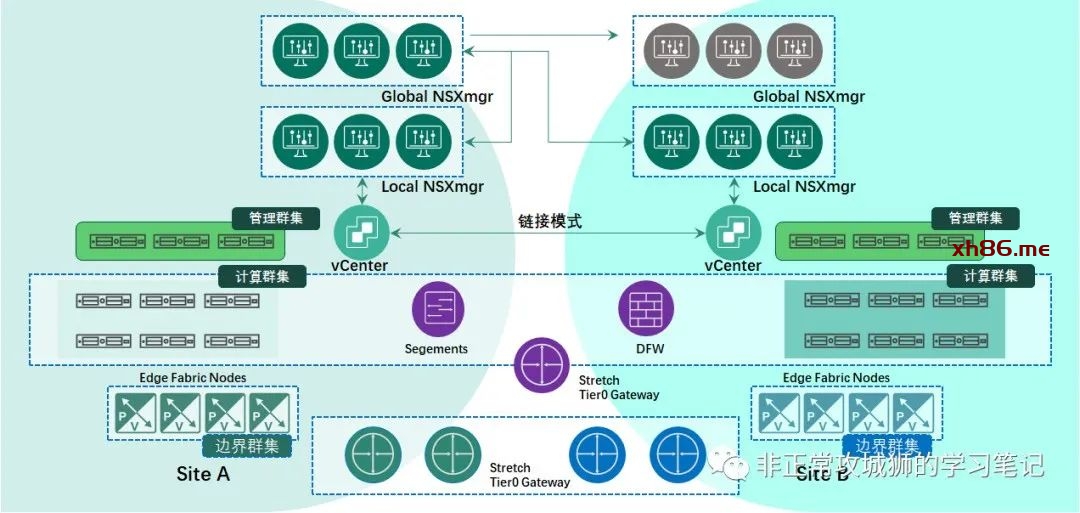
🔆01×03.F模型:NSX-T Federation
F模型中改变最大的还是管理平面架构,NSXmgr将分为两大类角色:用于接受全局管理员配置的Global NSXmgr,以及有一定区域局限性的Local NSXmgr。通常情况下,会有六台Global NSXmgr部署在两个数据中心,分别组成两个集群。两个集群以Active-Standby的方式承担Global NSXmgr的功能。Local NSXmgr有一定的区域局限性,每个区域/数据中心都可以有自己的NSXmgr集群,用于本地传输区域、传输节点的管理。不同区域的vCenter建议采用链接模式部署,更便于多活和容灾场景的实现。
本篇讨论的话题将围绕V模型、T模型和F模型来展开。
理由1:V即将是过去完成时
熟悉NSX的朋友一定知道,V模型即将成为历史。在单数据中心面前,向左走(V模型)还是向右走(T模型)的选择其实不难。凭借对容器网络、公有云、裸金属、KVM等VMware异构产品的支持,用户更倾向于选择NSX-T。但在面临多数据中心的场景时,用户往往会面对一定的纠结。纠结的原因有两个:
🐕. 主观上V模型能够实现两个(多个)数据中心的双活和Local Egress(本地输出),T模型无法真正意义上实现(得分成红蓝两种类型的流量,这个后文再谈)。
🐕. 客观上V模型即将成为过去完成时,且生态圈存在一定的局限性。
在鱼和熊掌不可兼得的情况下,V模型注定不会成为今后用户选择的途径。尽管他可以支持Local Egress这个非常重要的需求。
理由2:T存在一个悖论
我们再来回顾一下T模型的管理平面:三台NSXmgr组成的集群,同时作为多个数据中心的集中管理与控制平面。
那么问题来了:管理与控制平面的高可用性和高可恢复性如何来保证呢?
有人说,不是有三台NSXmgr组成的集群么?诚然,但仔细推究也会发现这三台服务器的部署的确存在一些限制。
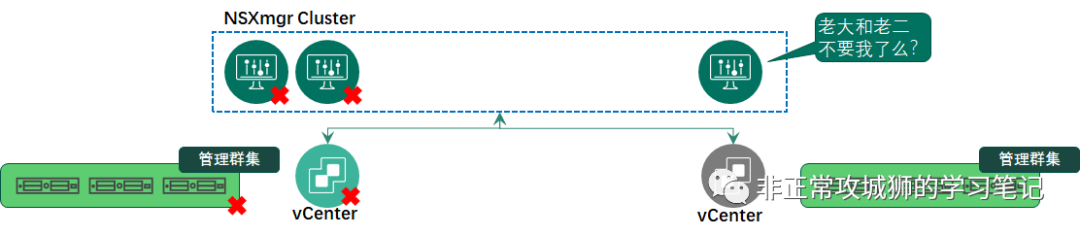
以两个数据中心来说,选择的方式无非是3+0或者2+1这种方式。当然如果是三个数据中心,从技术层面来说也可以通过1+1+1的方式来部署NSXmgr。
通常情况下,笔者会设计将3台NSXmgr以L2网络部署在同一个数据中心。原因有两个:
1>同一个数据中心的网络环境能满足NSXmgr集群内服务器之间不大于10ms延迟的要求
2>L2网络部署三台NSXmgr不需要额外的负载均衡器提供集群的VIP,能减少潜在的故障点。
如果不放到同一个数据中心,那情况会有变化么?答案是肯定的!
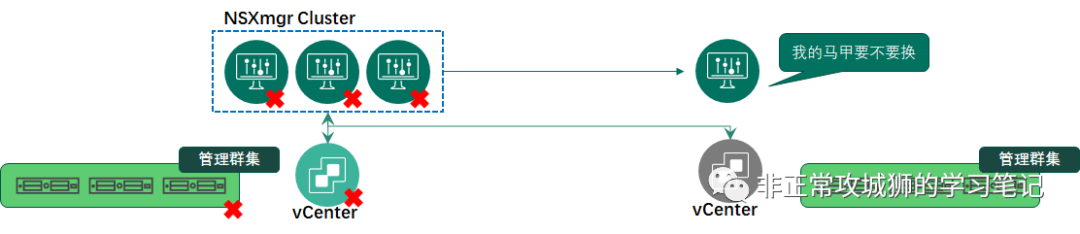
如果数据中心之间的网络延迟能满足不大于10ms的要求,NSXmgr服务器跨数据中心部署在技术上毫无疑问是可行的。我们先不考虑网络IP的问题,先来看看三台NSXmgr的部署方式。假定A数据中心有两台,B数据中心有一台。那么当B数据中心出现站点级的故障或者vSphere管理群集出现故障时,NSXmgr集群中有两台存活的服务器,可以继续对A数据中心站点的传输节点和NSX网络提供管理和控制功能。但是如果A数据中心出现上文提到的情况又会如何呢?此时集群内在B数据中心只有一台存活的服务器,虽然它的IP可达,但是它无法继续提供对B数据中心传输节点和NSX网络提供集中的管理和控制功能。因为对于这台NSXmgr而言,他只会认为自己是“被抛弃的那一台服务器”。
这一点其实和VCHA的机制非常像。如果管理员将Active和Witness两台虚拟机同时关机,那么当前是Passive角色的vCenter由于得不到两票(Witness和自己),不会将自己切换成Active角色,相关的核心服务依旧是停止的状态。NSXmgr集群的机制与VCHA相当类似,所以在2+1部署的场景下,可以简单理解为管理平面只有50%的可用性。
既然2+1的部署模型存在相当大的可用性风险,那么NSXmgr集群的部署尽量还是按照三台服务器位于同一个站点的方式来部署较为妥当。但这种管理平面的设计自然就会引入新的限制,也就是笔者标题内说的的“悖论”。
当NSXmgr集群所在的数据中心或者vSphere管理群集发生故障,且短时间内无法恢复的时候。管理员自然需要在其他数据中心重新“拉起”NSXmgr虚拟机。
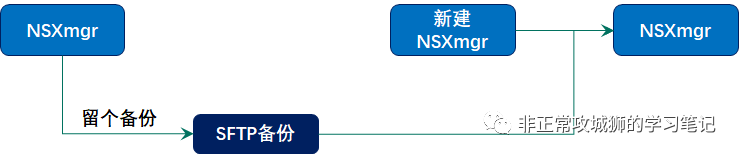
常用的做法是:通过恢复SFTP的备份文件来恢复NSXmgr,继续对外提供管理和控制服务。在管理员在另一个数据中心恢复NSXmgr的同时,NSXmgr的IP地址和集群VIP地址也一并恢复了。问题也就出在这里:另一个数据中心如何能保证NSXmgr的IP地址继续可达?如果说管理网络都已经实现了跨数据中心的L2延展,那用户为什么还要通过NSX来再做一次L2延展?这不就是悖论么?有人说,可以通过修改IP地址的方式实现。的确,但这需要再部署一台NSXmgr,然后逐个逐个替换,还需要更新DNS解析记录等等繁琐的一系列操作。
因此,T模型管理平面的高可恢复性存在一定的挑战,这也是用户需要F模型的很重要原因。
理由3:T的多活存在一定的局限性
如果用户并不在意T模型管理平面的问题。坚持采用T模型的跨数据中心设计,那还会遇到什么问题呢?为了说明这个“局限性”,我们需要对NSX网络的南北流量走向做些深入地分析。
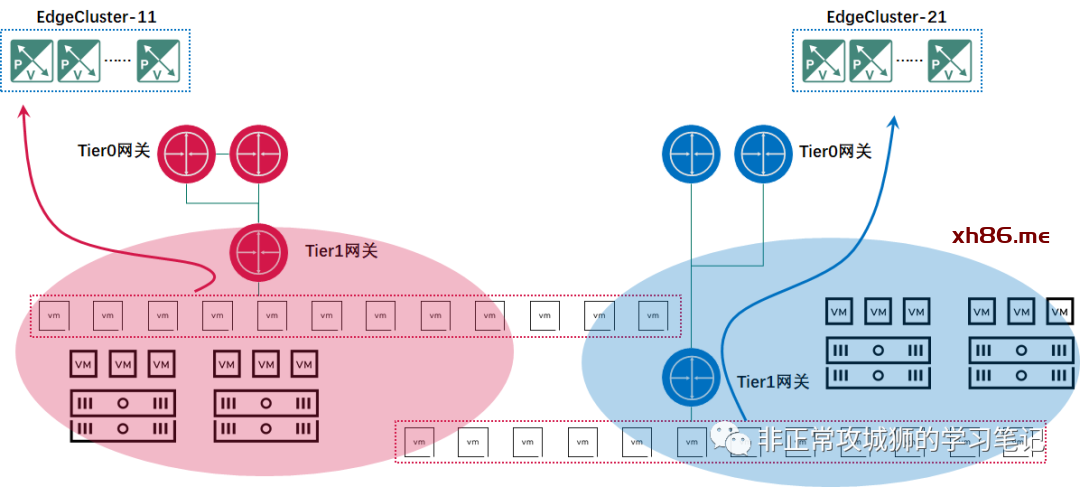
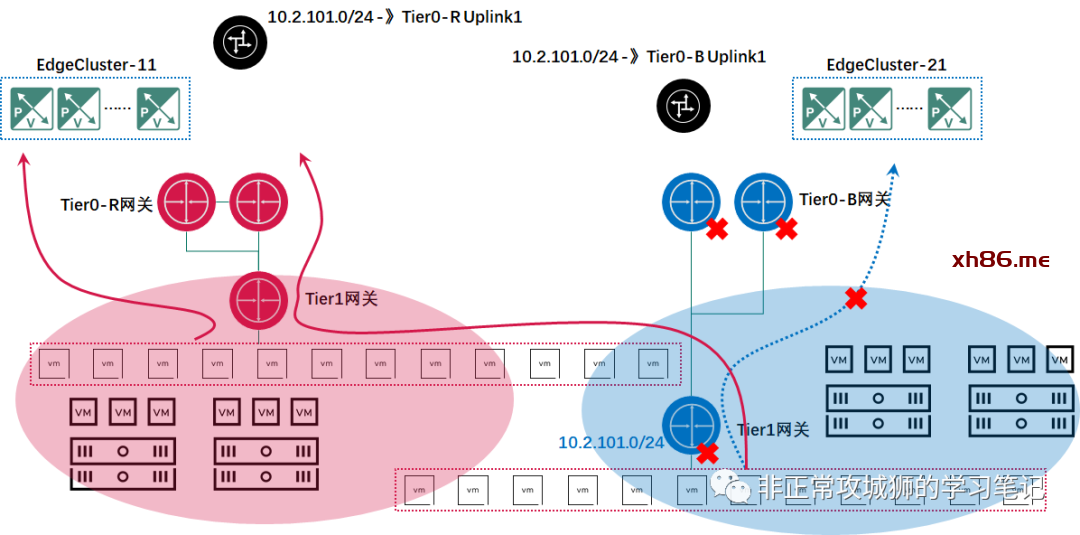
在T模型中,不同Edge集群是独立的,每个Edge集群承载的Tier0网关和其他集群的Tier0网关之间没有关联。在图中,红色的Tier0网关做为数据中心R的南北向边界设备;蓝色的Tier0网关做为数据中心B的南北向边界设备。接下来是Tier1网关,Tier1网关和Tier0网关一样,都需要“站队”,只能连接到自己所在数据中心的Tier0网关,且只能连接到一个Tier0网关之下。同样地,对于分段来说,也只能连接到一台Tier1或者Tier0网关之下。这就意味着,从分段到Tier1网关再到Tier0网关,只能是“非红即蓝”。虽然NSX的同一个Overlay传输区域可以覆盖数据中心R和数据中心B,这意味着实现了跨数据中心的L2连接,但是对于同一个分段内的虚拟机来说,无论它的位置是在数据中心R还是数据中心B,都只能通过一个数据中心的Tier0网关实现南北向的通信。
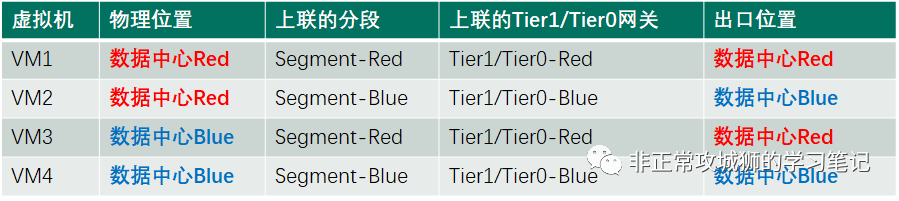
笔者罗列了一张表,不难看出T模型从宏观意义上来说的确是“多活”的。通过管理员合理的配置,多个数据中心的Tier0网关(出口)可以相对均衡地承载南北向流量。但是对于连接在同一个分段下的虚拟机来说,他们的流量只能通过单一的出口实现南北向交互,并不存在狭义上的“多活”。这是T模型无法解决的第一个问题。无法实现本地输出,会造成跨数据中心的Underlay存在大量的跨数据中心流量,这并不是最优的架构。
T模型无法解决的第二个问题,是出现Tier0级别或者Edge集群级别的故障时,管理员需要手动切换Tier1网关的上联才能恢复业务。
当然,要求出现Edge集群级别甚至站点级别故障场景时实现自动化的切换的确有点“吹毛求疵”,毕竟出现此类故障,肯定是需要人为介入的。但好的架构理所当然应该更加智能化、人性化、简介化。真正困扰管理员的,不是需要手动切换Tier1网关的上联(这种鼠标点点的操作和站点故障比起来,简直不值一提),而是路由的更新需要调整。
如上图所示,当蓝色的Edge集群或者站点出现整体的故障且短时间内无法恢复时,管理员将Tier1网关连接到Tier0-R网关之下。因为10.2.101.0/24是NSX内部网络,Tier0-R网关可以快速学习到下联路由。但对于数据中心R的物理设备来说,10.2.101.0/24原先是一个“不知道的网段,或者它下一跳的地址是Tier0-B的上行接口”,现在管理员需要添加路由或者更新该网段的下一跳地址是Tier0-R的上行接口。且这种变更可能还只是“临时性”的,等到数据中心B的故障恢复后,“还要改回去”。这是T模型不得不面对的第二个问题。
总体来说,T模型在多活架构下能够实现用户的大部分需求,但是存在一定的局限性。
联盟能解决问题么?
能!这是笔者经过实践后得出的答案。
回到F模型的拓扑本身:
来看看F模型能不能解决问题。
👉V即将是过去完成时
F模型是基于NSX-T数据中心产品的系统架构,且拥有良好的生态圈和可扩展性。
👉T存在的悖论
F模型的Global NSXmgr集群之间是跨三层的Active-Standby架构,集群内提供高可用性,集群间提供高可恢复性;不存在跨数据中心L2悖论。
👉T的多活存在一定的局限性
F模型的Tier0网关和Tier1网关是“Stretched Logical Router”,横跨多个区域/数据中心站点,能够实现本地输出以及自动故障切换。具体的实现方式,以及和V模型的对比笔者会在后续的连载中说明。