对于诸如两地三中心、多云容灾等命题来说,NSX是非常优秀的解决方案之一;实现上述命题的关键钥匙在于L2网络的跨数据中心延伸。就NSX解决方案本身来说,其构建的虚拟云网络能让用户在部署工作负载时,不必局限于地点,也不必拘束于网络限制,且能让工作负载在多数据中心之间实现无缝地迁移。
01
—
主机传输节点就绪
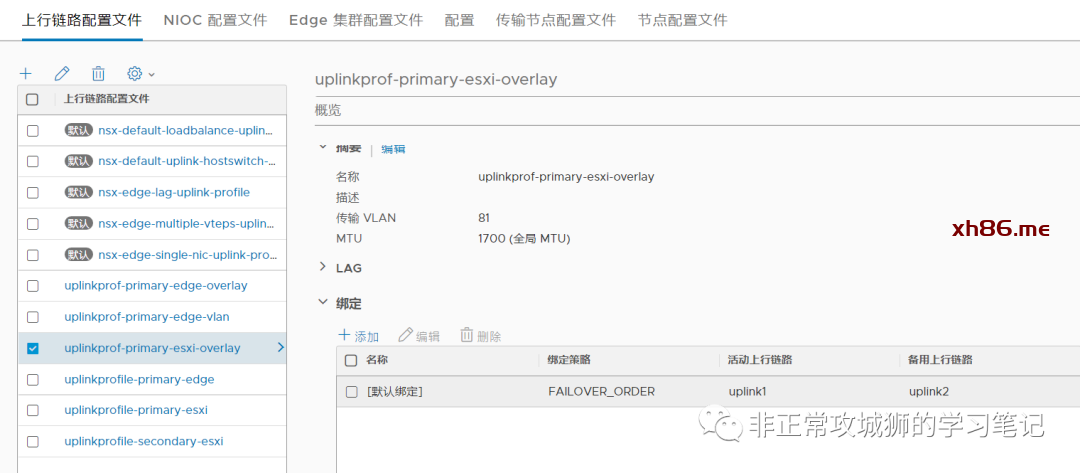
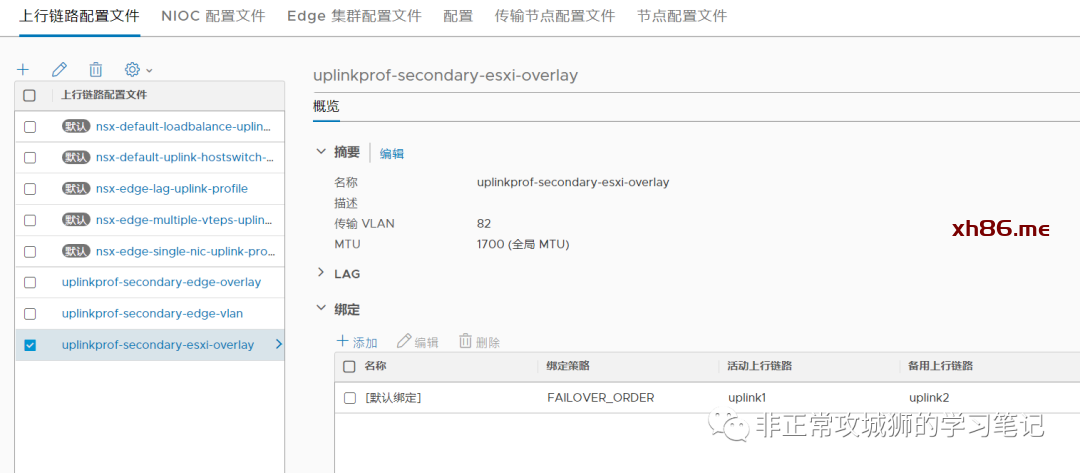
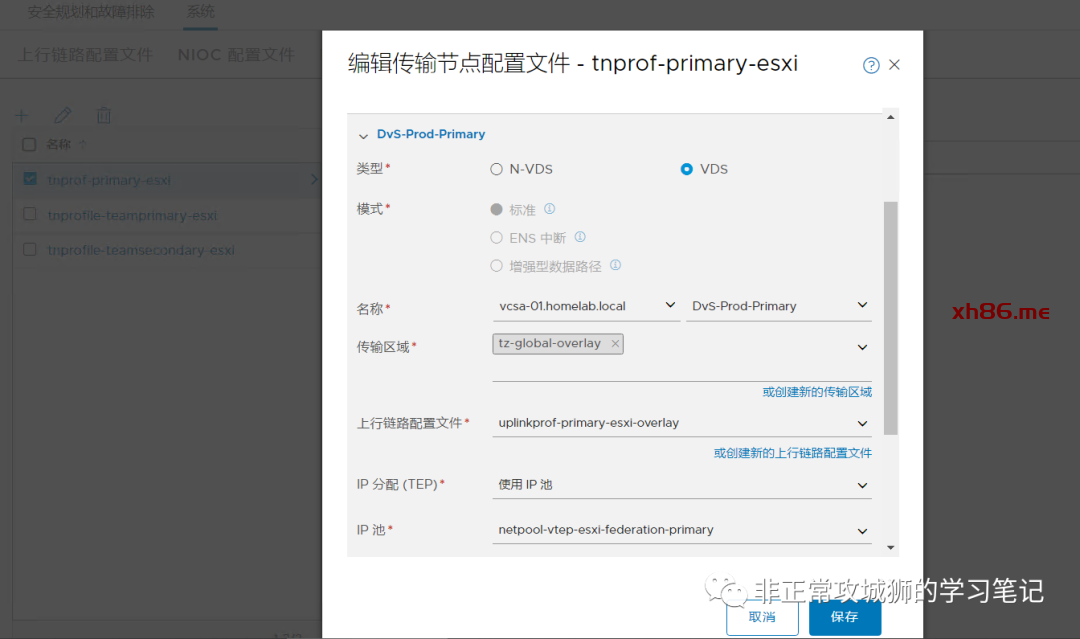
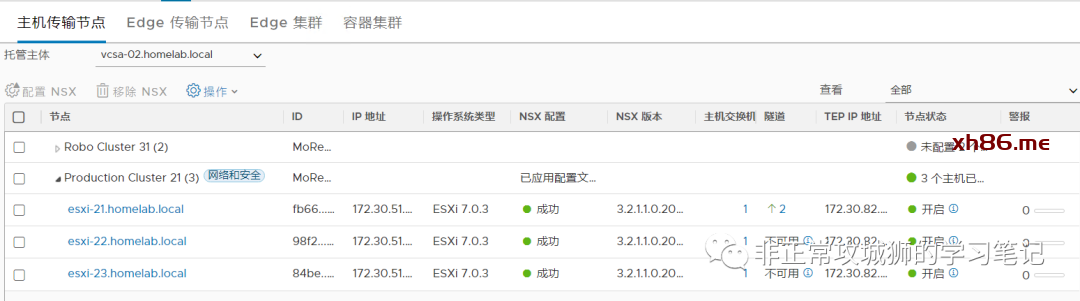
完成上行链路配置文件的定义后,分别完成两个数据中心的ESXi传输节点配置文件的定义。
本步骤需要注意的是,传输节点中关联的传输区域一定是Global Overlay传输区域。至于vTEP的IP分配采用静态方式、地址池还是DHCP不影响Federation的实现,各位朋友完全可以根据自己环境的实际情况来定义。

02
—
创建一个全局分段?
不!创建一个T1/T0网关
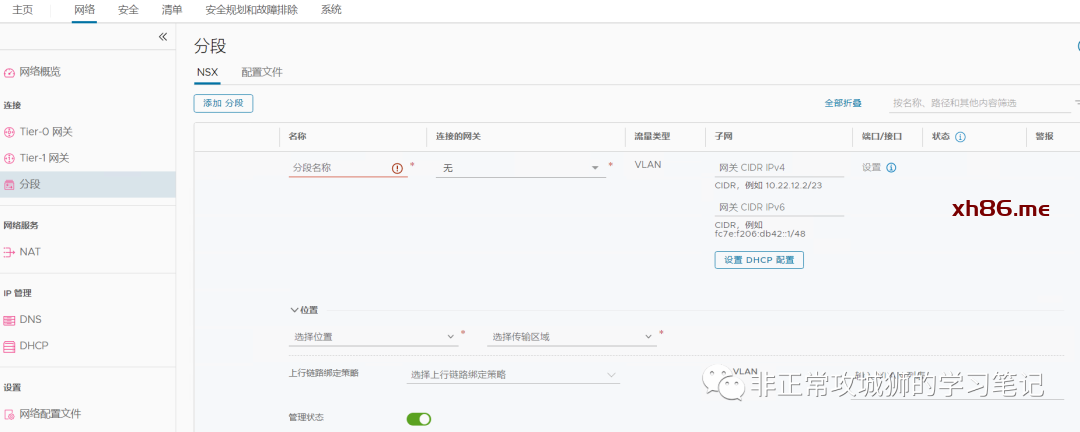
-
Edge池分配大小:路由,确保不会有Tier1网关的角色路由器被创建; -
暂时不创建Tier0网关; -
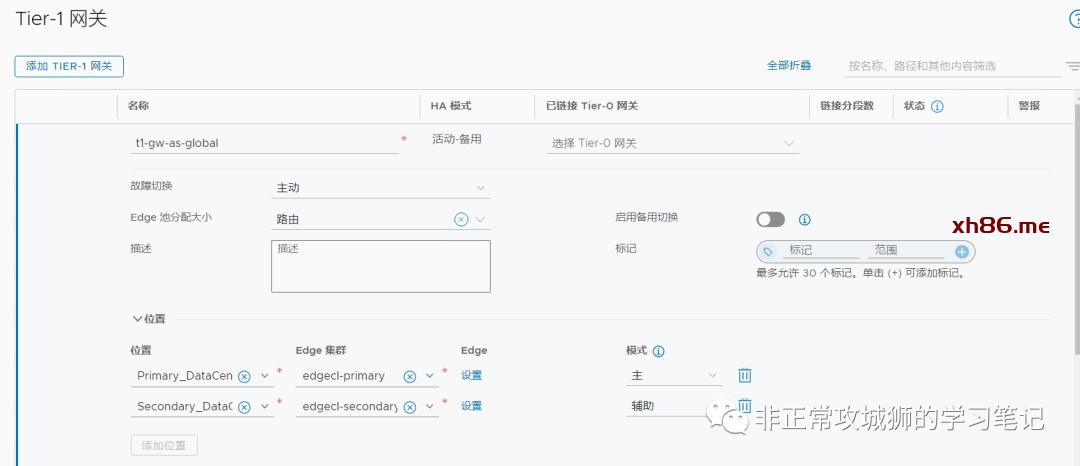
Tier1网关的位置会包含Primary DataCenter和Secondary DataCenter,Edge集群分别选上,其中定义Primary DataCenter和关联集群为“主模式”。
03
—
创建一个全局分段
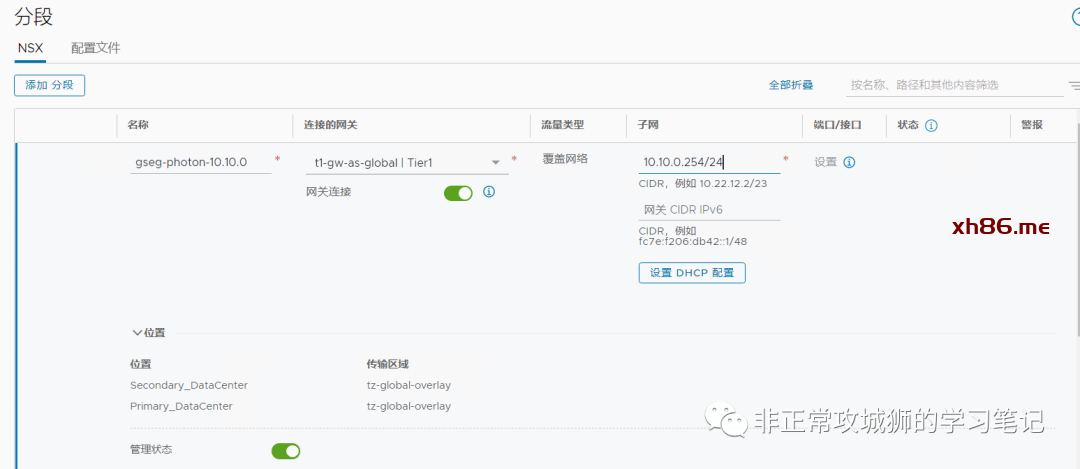
随后,在两个数据中心vCenter对应的分布式交换机上,都可以看到出现了新的一个NSX分段“gseg-photon-10.10.0.0”。
其中还有一个叫做“inter-site-bp-uuid”的分段,是系统自己创建的。不妨先“望文生义”一下:应该是用来实现跨站点分段延伸而自动创建的。

来验证一下吧:
1. 将Primary DataCenter虚拟机分别连接到对应的分布式交换机相关分段上
注意photon-11和photon-12是由不同的ESXi主机所承载的,这就表示Overlay流量必然会经过Underlay的传输。

同数据中心L2网络连通性:Photon-11与Photon-12之间L2互访正常。
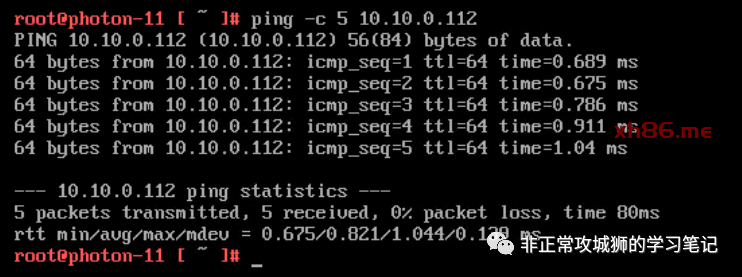
2.默认情况下,跨数据中心的访问是失败的。
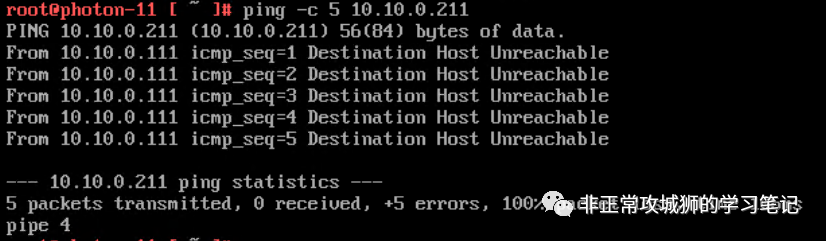
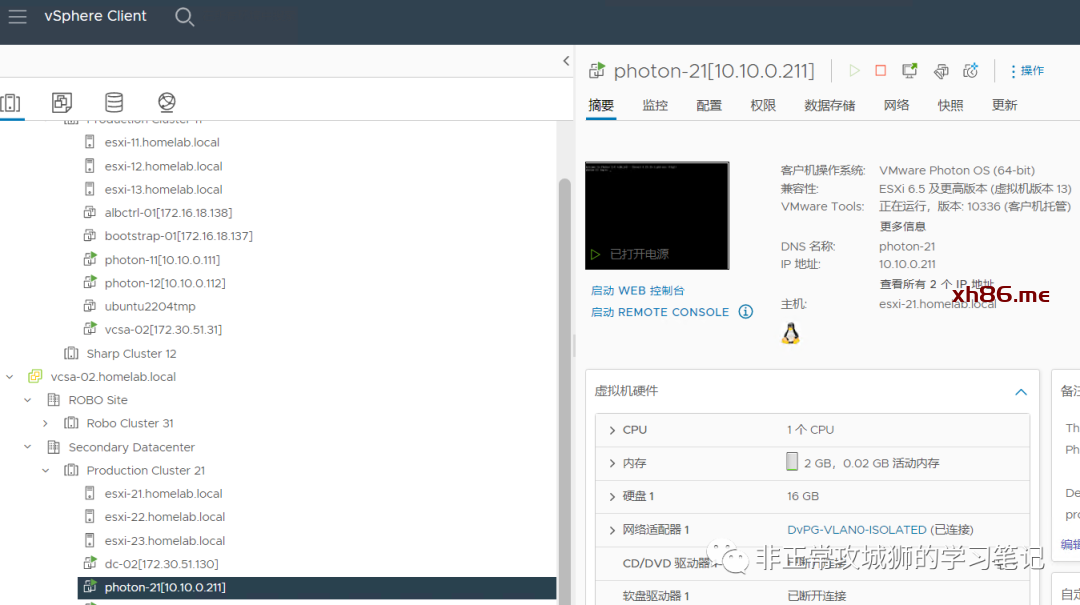
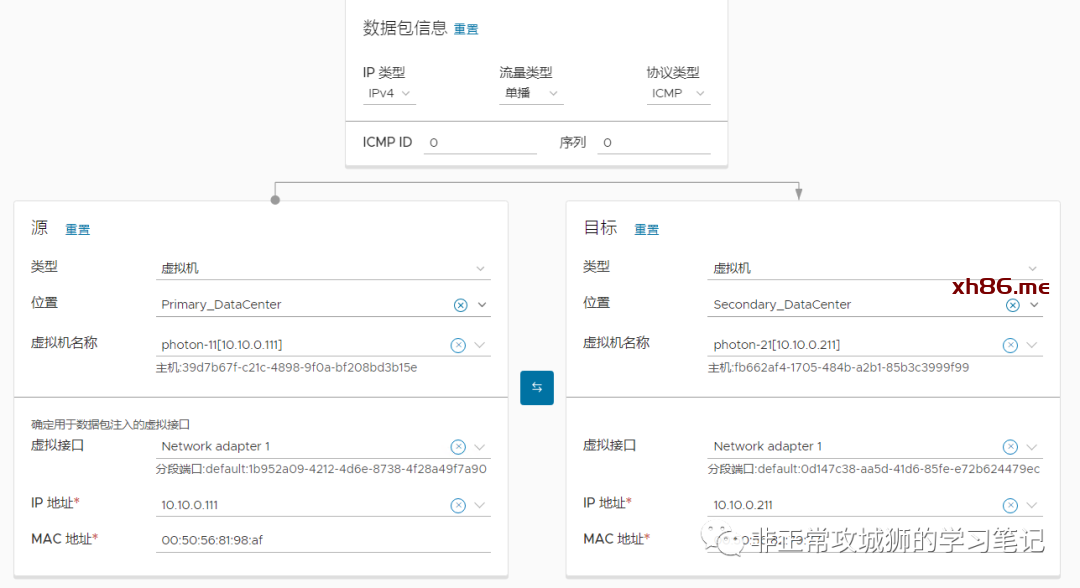
3.将Photon-21连接到Secondary DataCenter下分布式交换机对应的分段之上。
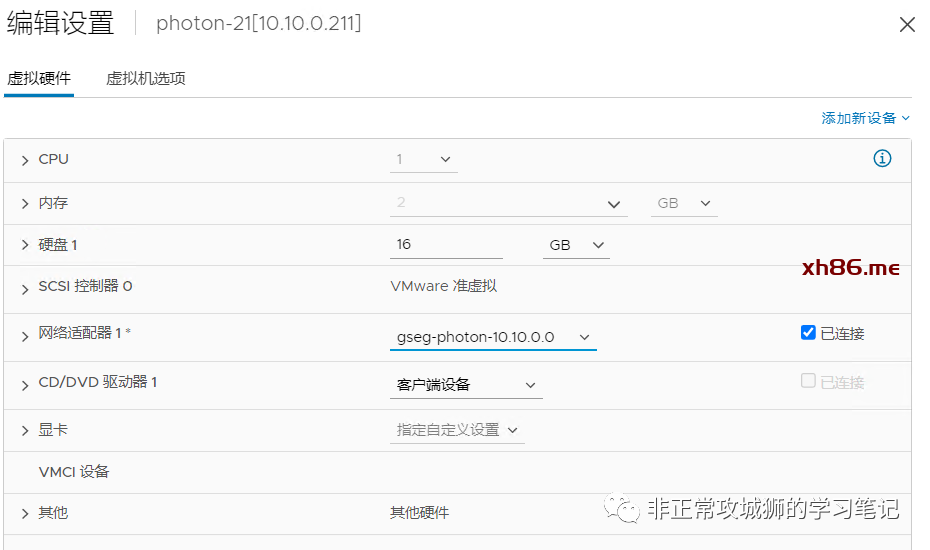
4.位于Primary DataCenter的Photon-11与位于Secondary DataCenter的Photon-21实现了跨数据中心的网络L2互通。

至此,我们完成了在Federation架构下,不同数据中心之间的全局Overlay传输区域的延伸,在该区域下的分段能够实现网络的跨数据中心L2可达,为业务多活、容灾和跨数据中心迁移提供了最重要的网络一致性基础。
04
—
来探索探索实现原理
虽然我们已经实现了基于全局分段的网络跨数据中心L2延伸,但笔者还是想深入探究一下其实现原理。因为如果工程师无法对基本的实现原理有所了解,一旦遇到故障排查的场景,就会手足无措一筹莫展。因此笔者尝试借助NSX自己的TraceFlow,来探索一下实现原理。
第一步,温故而知新。
对于NSX的标准分段来说,跨主机传输节点的Overlay传输区域的流量传输会涉及TEP封装。以下图为例:
当photon-11想要与photon-12通信的时候,从宿主机esxi-12和esxi-13的角度来说,他们之间的对话应该是这样的。

当然这中间涉及到ARP表、MAC表和TEP表的更新和同步,具体的原理和流程可以参加VMware官方的NSX ICM课程来进一步了解。

随后,如上图所示:photon-11的数据包经过NSX的vdl2模块到达TEP,经过封装后通过Underlay(VLAN81)网络转发到目标宿主机的TEP,目标宿主机接收到这个数据包后进行TEP的解封转,再经过vdl2模块转发到目标虚拟机photon-12,完成了这一次通信的过程。归纳来说,不同宿主机之间的Overlay流量传输必然经过了TEP的封装/解封转。
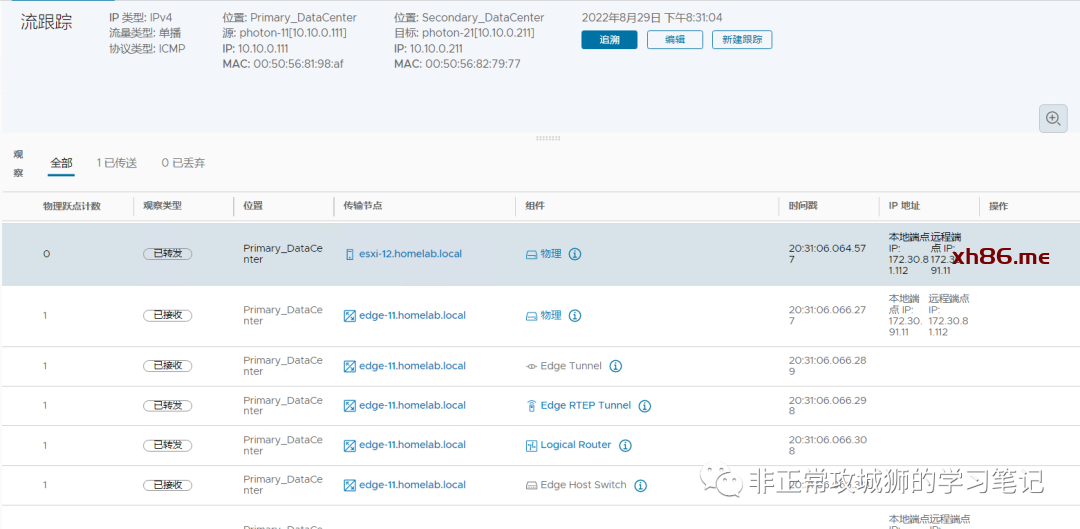
通过NSX自己的TraceFlow工具,也能清晰地看到这个过程:
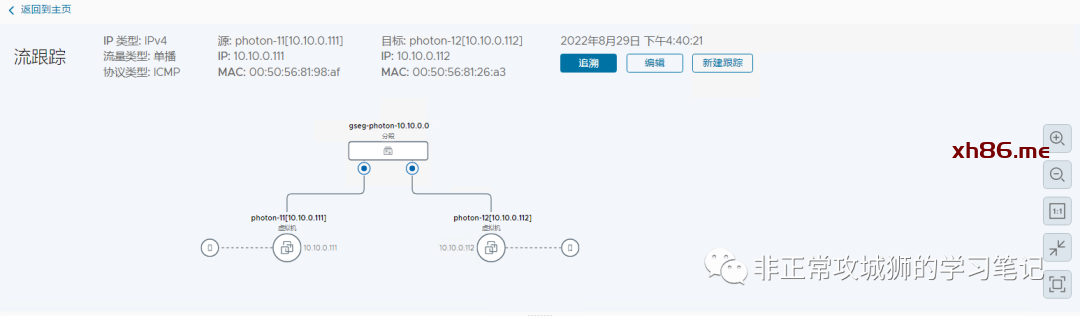
由于屏幕显示的限制,笔者只能截取最关键的TEP封装和Underlay转发部分。
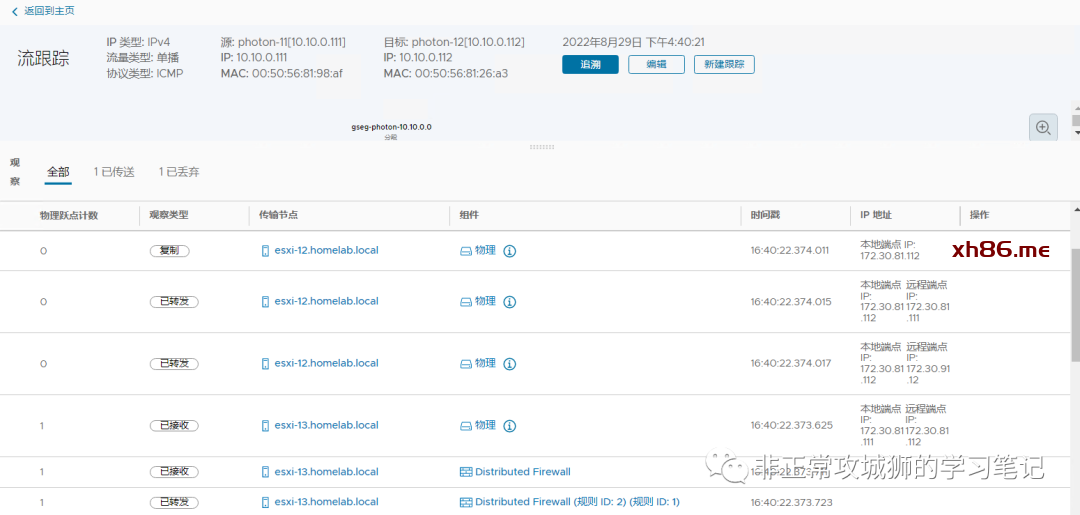
看到这里,我们是否可以温故而知新:跨数据中心之间的Overlay流量也是直接通过ESXi主机之间的TEP实现封装与解封装,然后经过Underlay网络来转发的!
这是一个合情合理的猜想,其流量转发如下图所示:

可事实真的如何么?
第二步,实践出真知。
在NSX上通过TraceFlow工具进行验证:
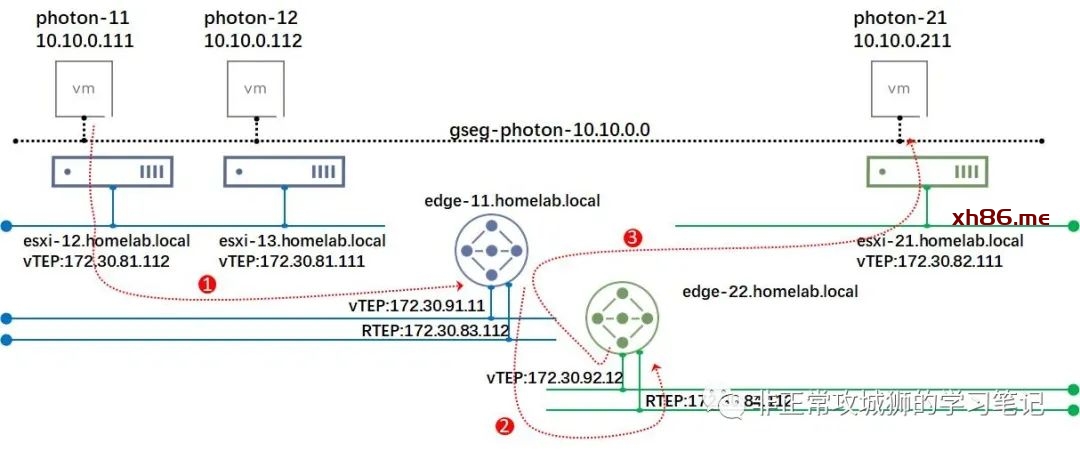
看来结果并非如此。实际上跨数据中心的L2通信,是通过Edge传输节点的Remote TEP来实现的。在下图中,大家可以清楚地看到这个步骤。