-
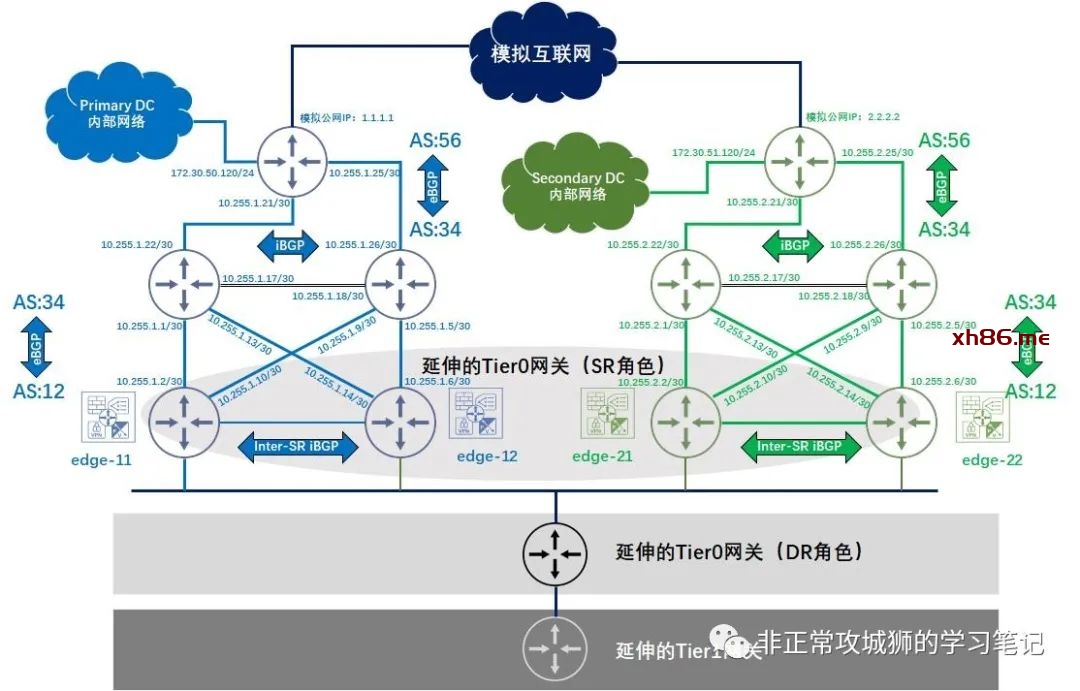
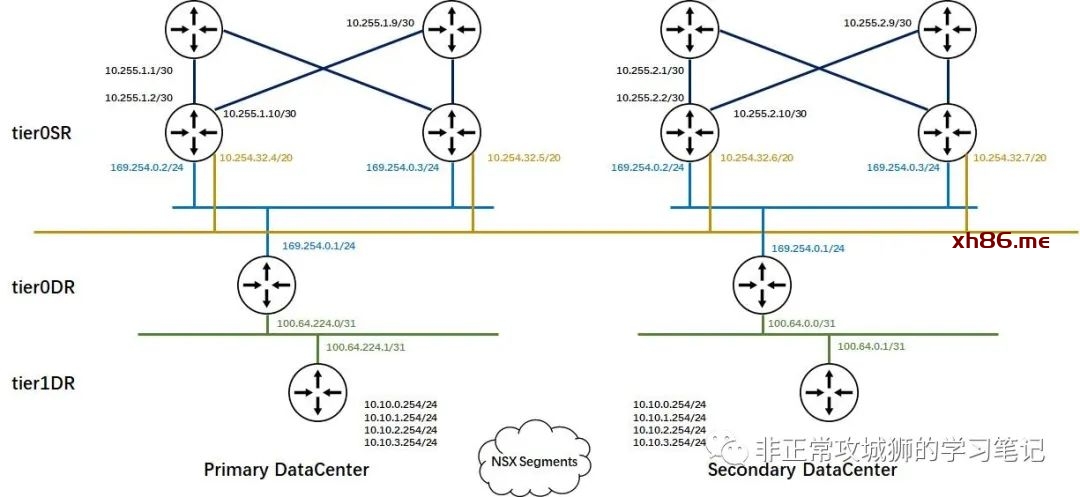
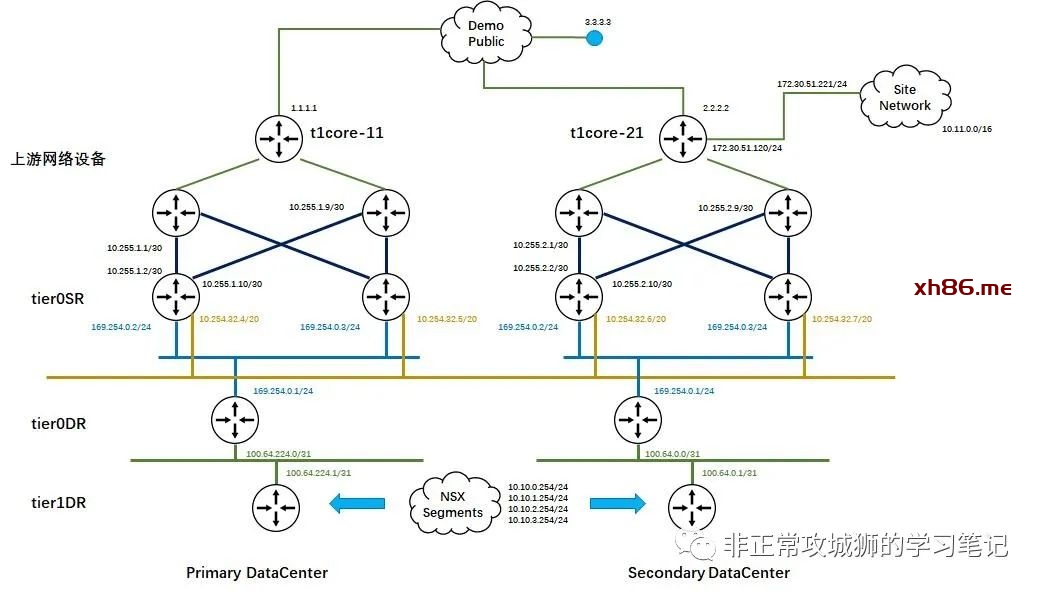
从整体网络拓扑来看,两个数据中心Primary DataCenter和Secondary DataCenter分别有自己的Tier0网关、上联网络设备、互联网出口网络设备以及各自的内部网络。
-
因为每个数据中心都有2台Edge传输节点,因此每个数据中心分别有2台Tier0SR角色承载NSX南北向网络流量。与之相呼应的是每个数据中心有2台物理网络设备与Tier0SR角色以“|X|”拓扑互联。为了减轻NSX逻辑网络变更给管理员带来的工作量,NSX Tier0网关采用BGP路由协议与上游网络设备互联。
-
在每个数据中心物理网络设备的上游,各自有1台互联网出口设备用于互联网连接,同时该设备还会有一个“Ramp to Local Network”的出口用于和各自本地的内部网络互联。在两个数据中心之间并没有除了TEP网络以外其他L3/L2可达的链路,因此两个数据中心的传统网络之间没有互联,是相互独立的网络。
截止到上期的分享,各位已经跟随笔者完成了NSX管理与控制平面的安装部署、Edge传输节点的就绪、主机传输节点的就绪、NSX网络的二层及三层互通等设置。为了实现上面的拓扑,接下来我们将开始进行Tier0网关上行链路的配置与调试。
如拓扑所示,每个数据中心的2台Tier0网关分别有2台上游物理网络设备与之以”|X|”互联,这就意味着每个数据中心分别有4个VLAN传输区域的分段需要被创建,如下表所示:
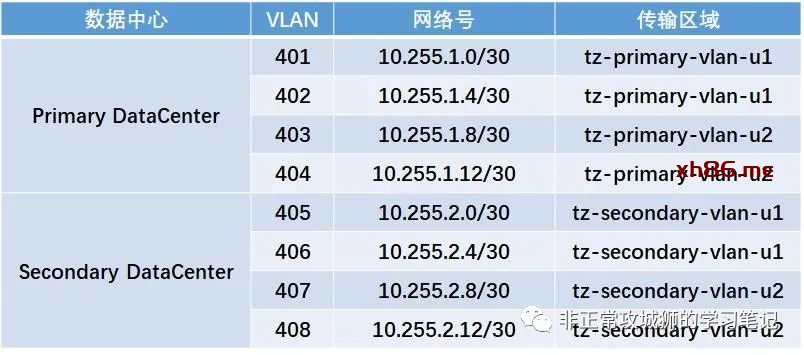
虽然上述分段关联的VLAN传输区域并非是“Global VLAN传输区域”,但依旧需要管理员在Global Manager上进行配置。
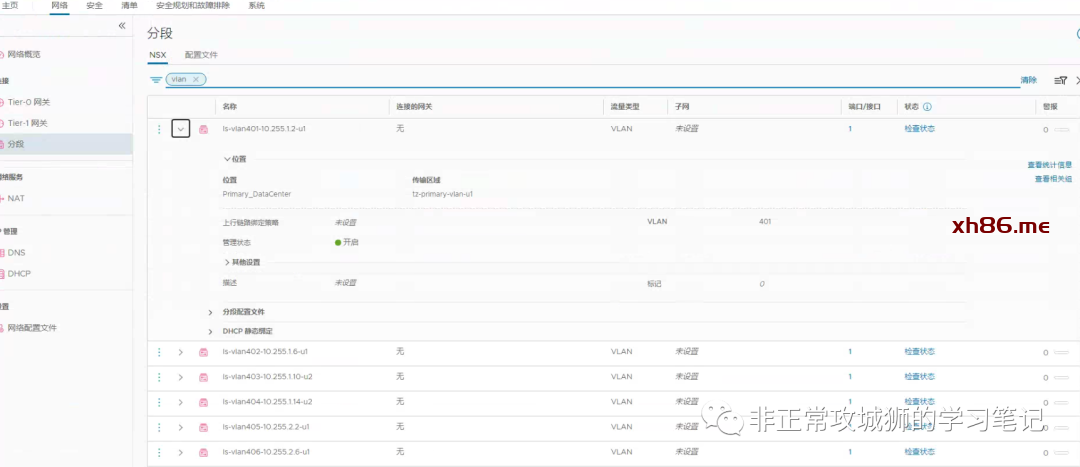
为了将创建的分段与对应的数据中心关联起来,需要为其定义“位置”,因为每一个位置对应了一个Local Manager集群,系统会自动检索并呈现可供管理员选择的“本地VLAN传输区域”,根据上表的设计依次完成所有VLAN传输区域分段的创建后,再开启下一步配置延伸Tier0网关的设置工作。
值得一提的是,如果管理员访问Local Manager是可以查看这些分段的,但这些分段虽然可被管理员编辑,但无法被删除,因为他们是被标记为“GM”管理的分段。
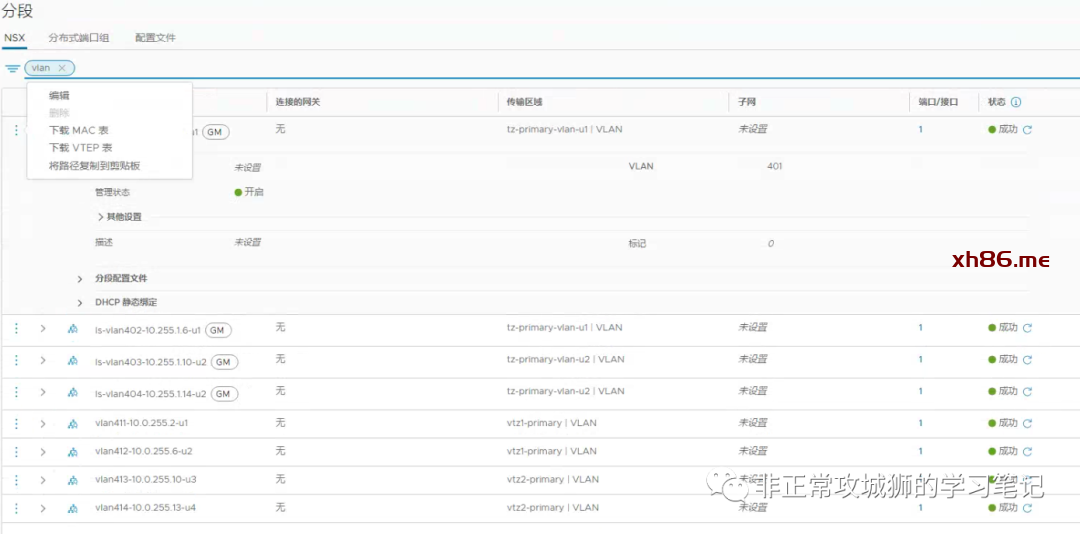
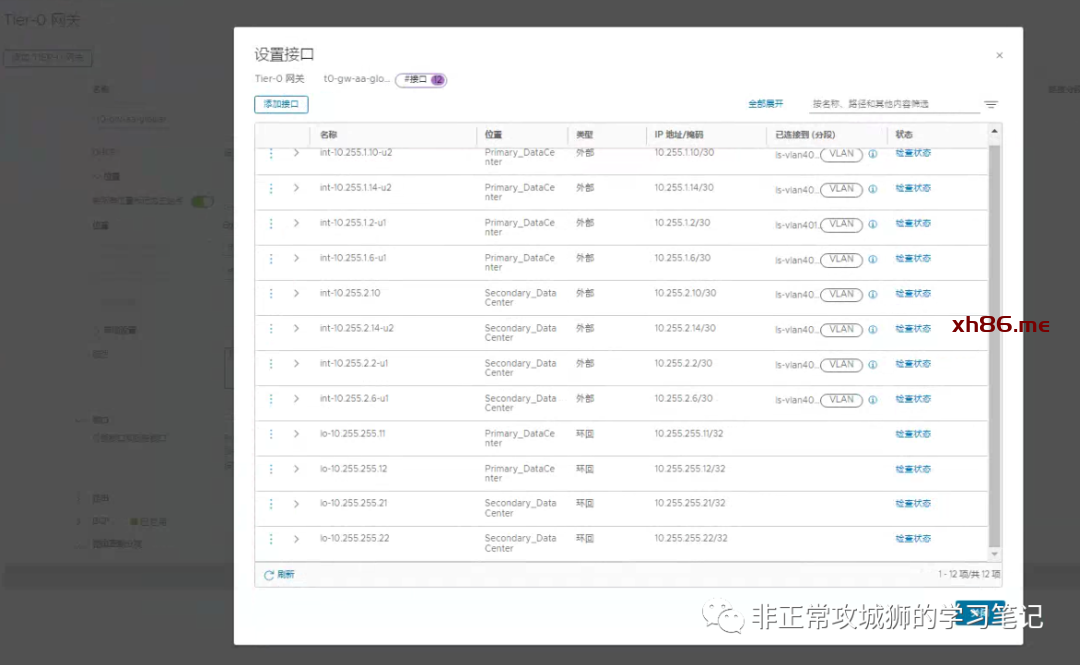
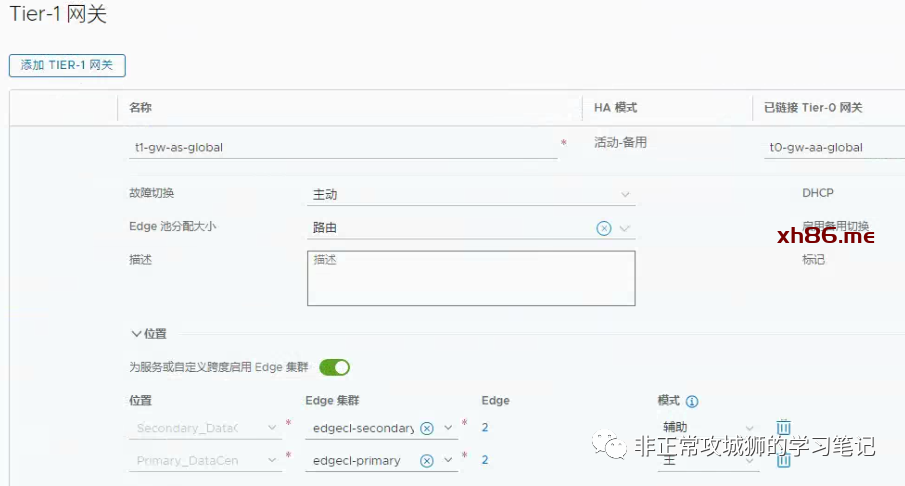
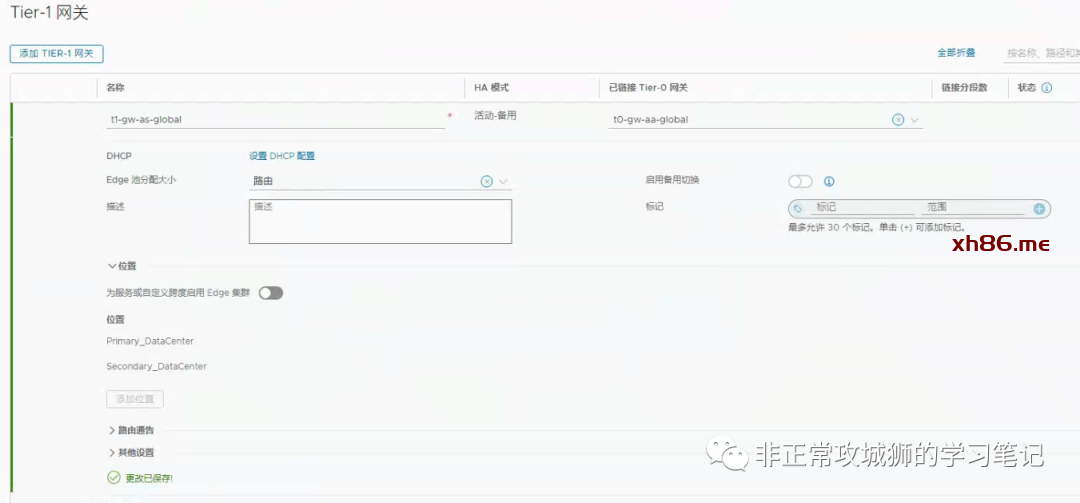
如上图所示,笔者的Homelab环境中一共定义了12个接口。其中8个用于真实的南北向流量交互;4个环回地址分别设置给4台Tier0SR实例。在延伸的Tier0网关上创建接口比普通的Tier0网关会增加一个关联“位置”的步骤,其目的和创建VLAN传输区域的分段时关联“位置”相同。
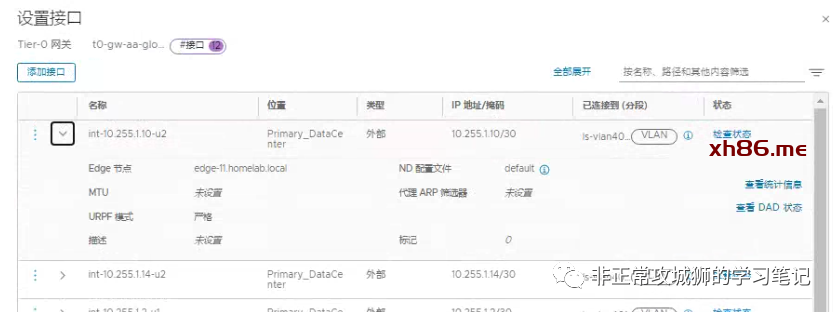
笔者的环境中,每个数据中心有2台Edge传输节点分别关联2个VLAN传输区域,因此每个数据中心合计有4根上行链路,稍后还需要对每一根上行链路定义BGP邻居关系。
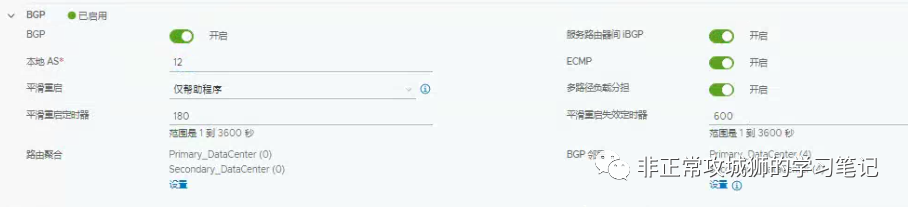
在创建BGP邻居关系之前,需要对Tier0网关的BGP参数进行一些全局的定义。
-
BGP:开启。 -
服务路由器间iBGP:开启;对于同一台Edge传输节点会承载2根以上不同上行链路的场景,必须要开启BGP以避免出现路由黑洞的问题。而NSX Federation架构下开启服务路由器间iBGP更是实现内部网络异地访问的必要条件。 -
本地AS:12,根据拓扑和实际情况来定义。 -
ECMP:开启;在多链路+Tier0网关是A/A部署模型的情况下,开启ECMP可以提高吞吐。
接下来为每一个接口定义BGP邻居关系:
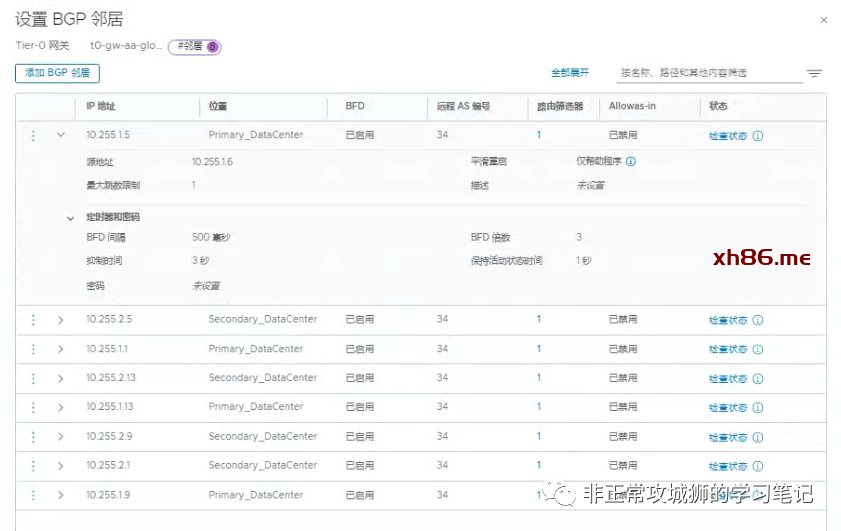
邻居关系添加完成后,管理员可以点击“检查状态”来查看邻居关系是否正常。
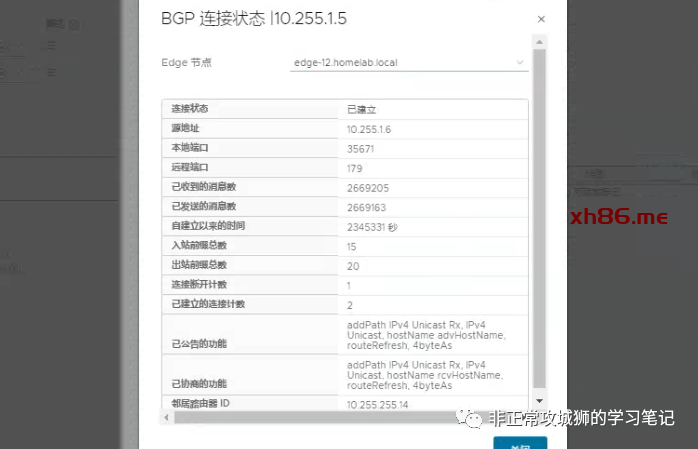
此时上游物理网络设备还无法学习到NSX逻辑网络网段,原因是缺少了管理员定义“路由重分发规则”的步骤。与普通Tier0网关不同的是,延伸的Tier0网关在定义“重分发规则”的时候,需要为不同的数据中心(位置)分别去定义的。

在笔者的环境中,Tier0网关级的路由重分发策略如下:

Tier1网关级的路由重分发策略如下:

为了更快速地实现故障切换,也建议大家在实际项目中配置BFD来实现路由的快速收敛。在本示例中因为采用BGP路由协议,在创建邻居的时候就可以激活BFD开启选项;而对于采用静态路由协议的场景来说,需要手动设置“静态路由BFD对等体”。
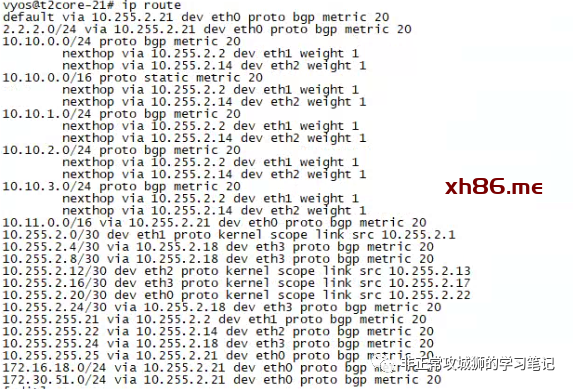
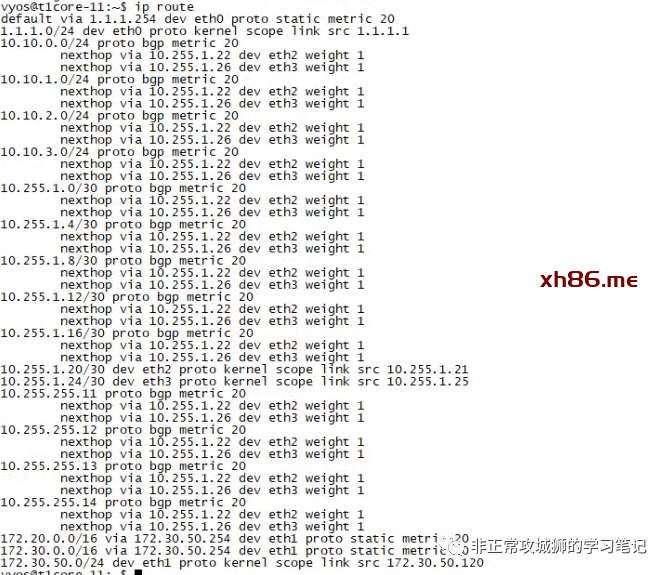
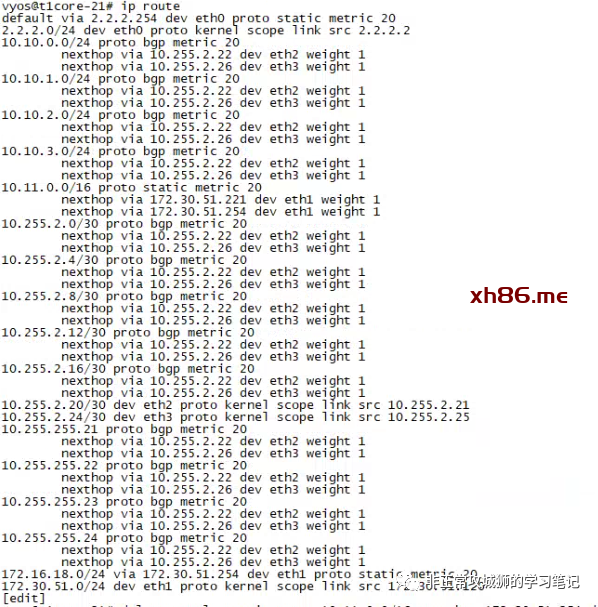
至此,与路由相关的参数设置全部完成。通过上游网络设备的命令行,可以看到通过BGP协议学习到的路由条目。
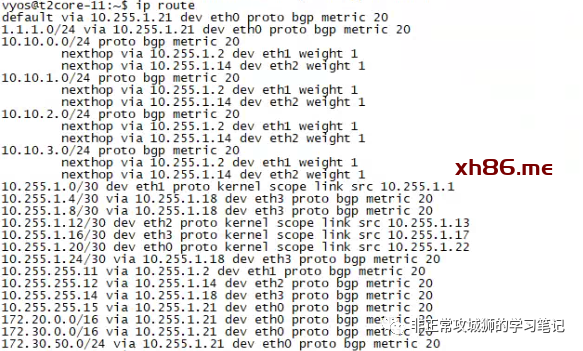
对于这台上游网络设备而言,NSX网络(10.10.0.0/24、10.10.1.0/24、10.10.2.0/24、10.10.3.0/24)已经通过BGP协议被学习到。因为同一个数据中心的2个Tier0SR实例各自都会有2根上行链路分别连接到2台上游物理网络设备,因此可以看到每一条学习到的路由都存在2个路径(如本示例中的10.255.1.2和10.255.1.14,分别对应Edge-11和Edge-12内核中运行的Tier0SR实例。)
无论是在Primary DataCenter(集群主站点)还是Secondary DataCenter(集群辅助站点)的Edge传输节点中,都可以看到Tier0SR和DR以及Tier1SR和DR实例运行。
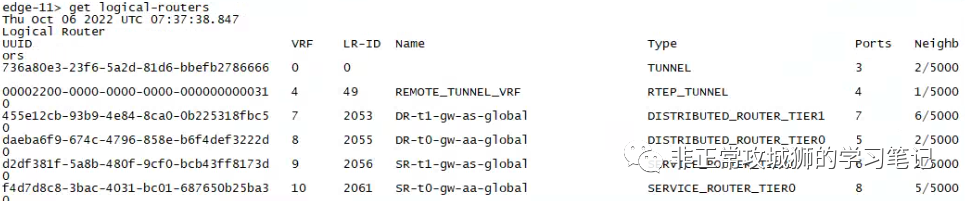
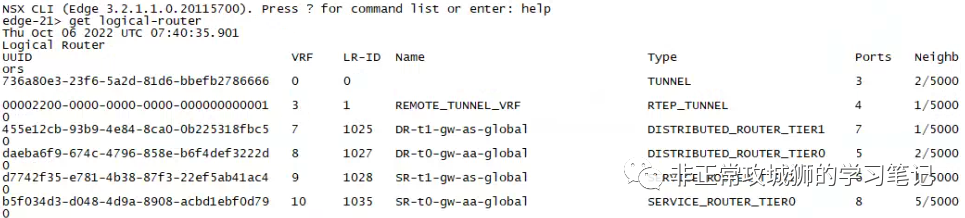
今天我们就来继续上一篇未尽的讨论,在有Tier1SR和无Tier1SR两种场景下,Federation架构的南北向流量究竟是如何被路由和转发的。
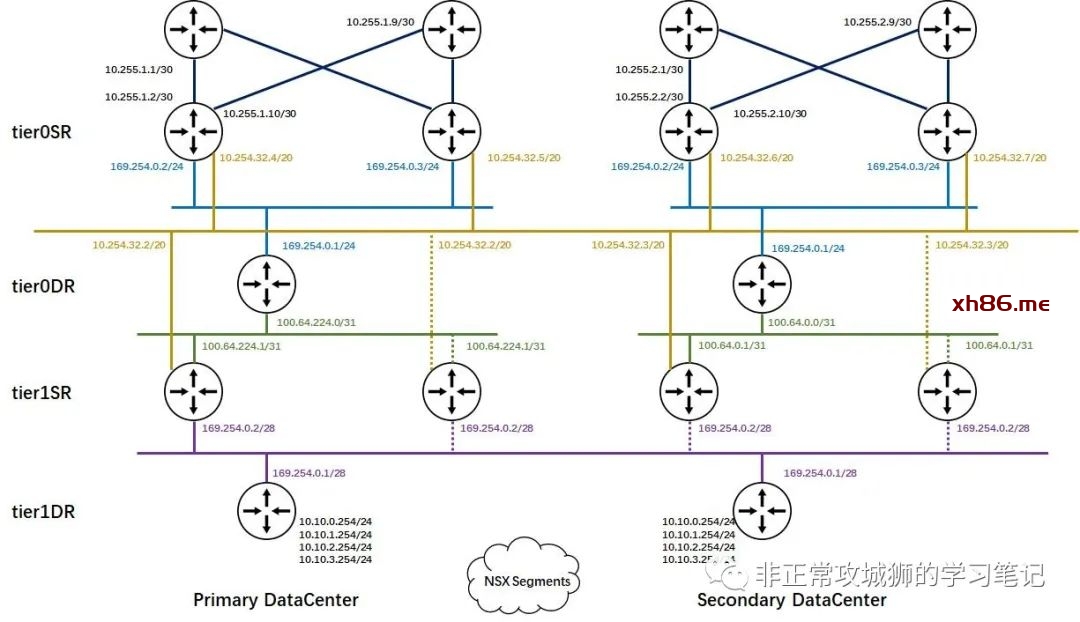
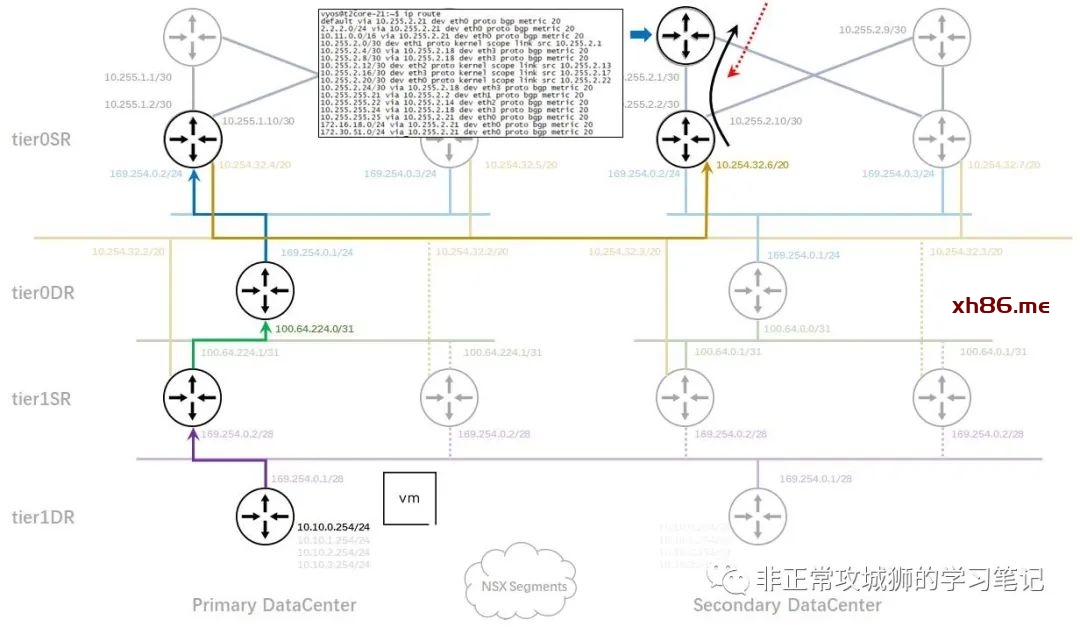
有人或许会有疑问,为什么10.254.32.0/20和169.254.0.0/31这两个分段会被笔者描绘成延伸分段。其实这个只需要在Edge传输节点上用命令“get logical-switches”就能判断。
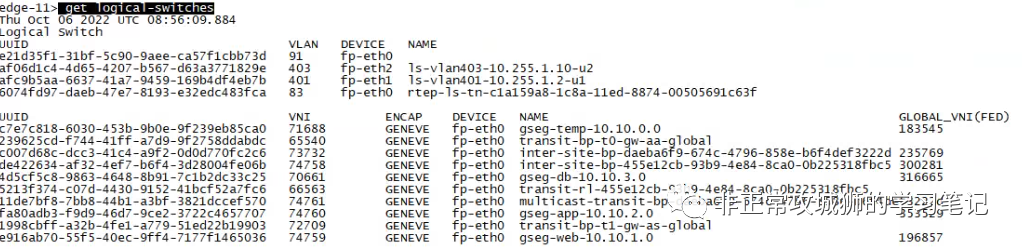
如上图所示,所有Global Segments都会有一个Global_VNI标识符,其中包括4个管理员手动创建的业务分段和2个系统自动创建的内联传输分段。
在笔者描绘的内联拓扑上,可以看到有一些接口是虚线。这是因为SR角色上连接到同一个分段上的两个接口如果是相同的IP地址,一定只会有一根链路是正常承载流量的,其他几根链路都是备选路径,这符合Tier1SR只能是Active-Standby模型的原理和客观实际;通过Edge传输节点的首选和备份关系,不难得出默认情况下只有edge-11传输节点内核中运行的实例才会是“实线”连接的结论。
进行到这里各位已经不难推测:在有Tier1SR实例的场景下,所有连接到Global Segments的虚拟机与外部网络交互的流量一定会经过Primary DataCenter的首选Edge传输节点。
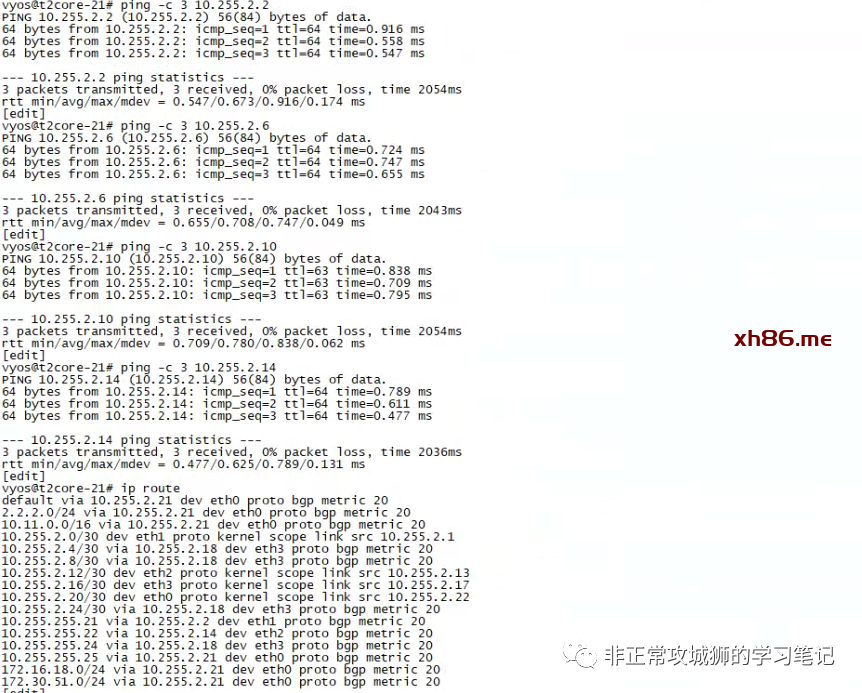
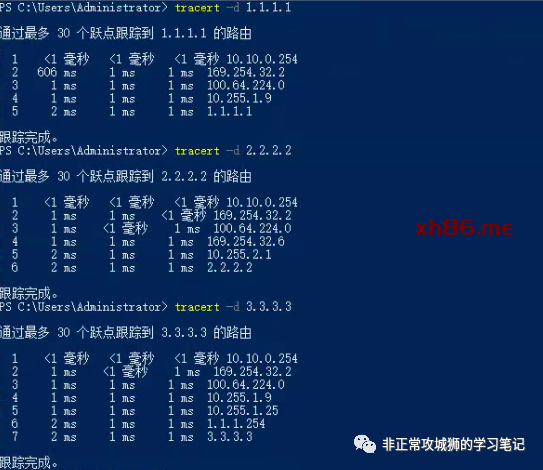
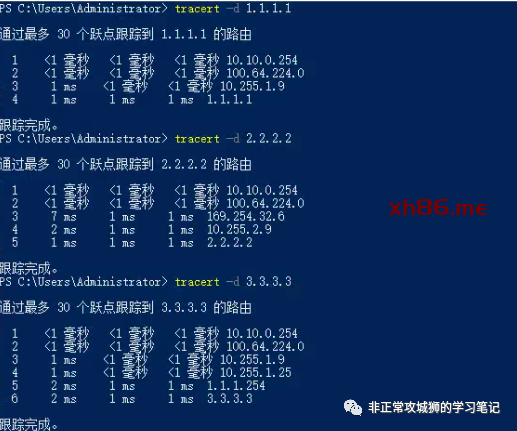
为了验证这个想法,笔者用一台Primary DataCenter的虚拟机10.10.0.12TraceRoute模拟的公网IP3.3.3.3。
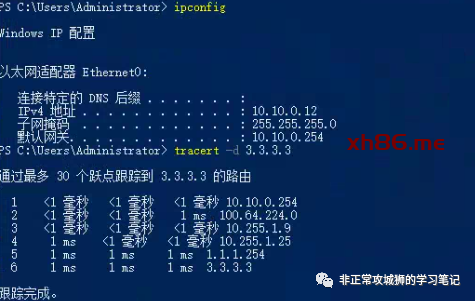
可以看到这个流量经过10.255.1.9(Primary DataCenter的上游网络设备)到达1.1.1.1的出口后,最终被转发到目的地3.3.3.3。
当笔者尝试PING Secondary DataCenter的出口地址时,发现默认情况下该PING包竟然不可达!
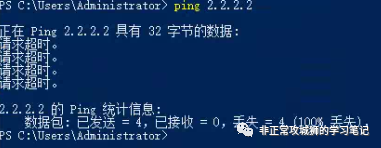
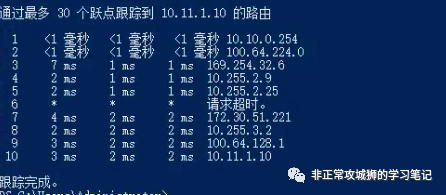
通过TraceRoute命令进一步查看流量路径。
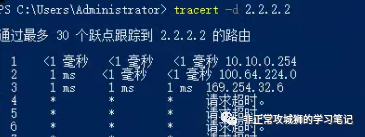
如下图所示,根据TraceRoute命令的结果,笔者将流量经过的路径描绘出来:
该流量的确可以通过内联拓扑转发到Secondary DataCenter的某一台Tier0SR,并且经过上游网络设备的转发到达2.2.2.2;但是当数据包尝试回来的时候,由于上游网络设备没有学习到10.10.0.0/24的路由条目,因此默认情况下不会将数据包发往Tier0SR的上联。
在实践过程中,笔者也一度以为是自己的Homelab环境本身的问题。Secondary DataCenter与上游路由器之间没有正常建立邻居关系或者路由分发策略所写有误。但在仔细检查配置后,发现的确不是网络连通性的问题。
对于这个问题的解决方案其实很简单,只需要在Tier0SR的上游网络设备添加静态路由,将10.10.0.0/16(笔者的NSX环境业务网络CIDR)的下一跳地址指向Tier0SR的上联接口即可。在完成静态路由的设置后,发现已经可以正常访问2.2.2.2网络了。
现在将该虚拟机迁移到Secondary DataCenter。
如下图所示,通过宿主机的IP地址可知,该虚拟机已经被迁移到Secondary DataCenter。
通过下方的演示用例不难得出以下几个结论:
1. 中间多了一跳169.254.32.2,这是Primary DataCenter的Tier1SR的接口地址,意味着流量经过了RTEP封装后,从Secondary DataCenter的Tier1DR被转发到Primary DataCenter的Tier1SR;
2. 10.255.1.9以及10.255.1.1这两个Primary DataCenter上游物理网络设备接口地址的出现,更验证了在Tier1SR存在的场景下默认所有数据中心NSX内部与外部的南北向流量一定会经过Primary DataCenter设备。
3. 对于Secondary DataCenter内部网络的路由需要借助静态路由协议来实现(比如2.2.2.2这个IP地址)
4. 在有Tier1SR的场景下,“本地输出”的功能默认无法实现!
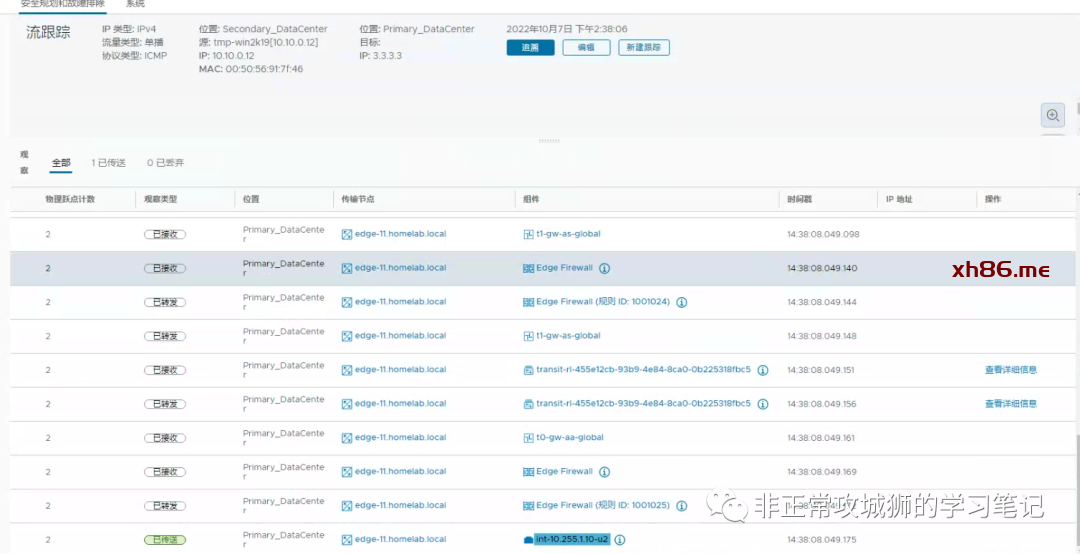
使用Global Manager的TraceFlow同样可以验证这个事实。
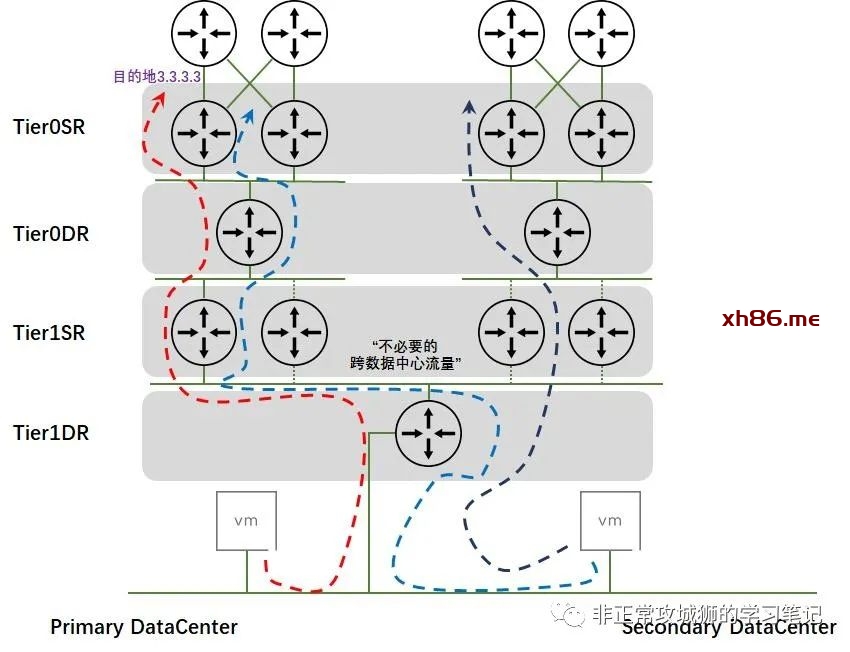
因此,这就是“本地输出”的必要性之一。此外,如果有两个不同的Tier1SR分别以Primary DataCenter的Edge传输节点和Secondary DataCenter的Edge传输节点作为自己Tier1SR的活动节点,那么同一个数据中心内不同Tier1网关下联的分段之间互访同样会经过数据中心之间的链路,这更加是“不必要的跨数据中心流量”,就好像下图所示的那样。当然严格意义上来说,这并不是“本地输出”讨论的范畴。
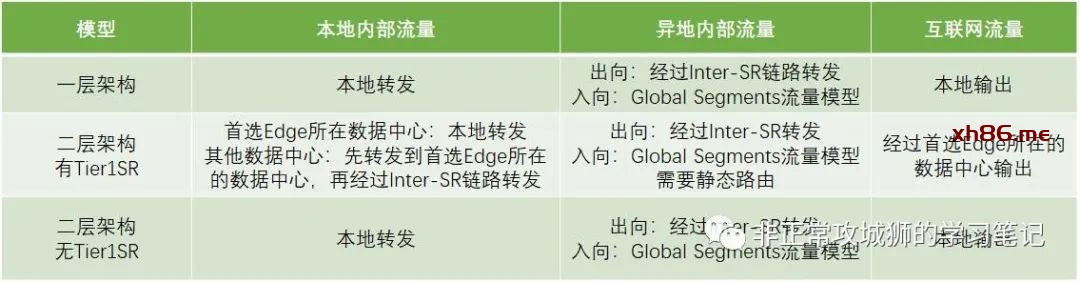
总结来看,在Tier1SR存在的场景下,NSX Federation在流量路径上和Multi-Site模型是相类似的。因此想要实现“本地输出”,只能是以下三种方式:
-
不为跨数据中心的延伸Tier1网关分配Edge集群,即不创建任何Tier1SR角色; -
不创建任何Tier1网关,所有虚拟机连接的分段全部连接到Tier0网关。 -
上述两种方式混合使用。


可以看到,此时的内联拓扑中不存在任何的虚线,本着“先路由后转发”原则,所有去往互联网的流量全部会由虚拟机所在数据中心的Tier0SR北向转发;这一点可以通过在虚拟机命令行用TraceRoute命令来验证。

因为没有了Tier1SR实例,因此前往2.2.2.2的数据包不会再经过Primary DataCenter;真正的改变是“去往3.3.3.3的数据包直接通过Secondary DataCenter的NSX网络和上游网络设备经过2.2.2.2的出口转发的”,实现了“本地输出”的功能,避免了“不必要的跨数据中心流量”转发。
接下来,笔者将虚拟机重新迁移回Paimary DataCenter,再使用TraceRoute命令查看数据包经过的设备:不难看出,这也是符合“本地输出”的流量路径。
至此,我们可以轻松归纳出2个结论:
1. 在Tier1SR存在的场景下,Federation无法实现本地输出功能;
2. 在除了Tier0SR以外,没有其他Tier1SR存在的场景下,无论是一层网络还是二层网络拓扑,Federation都能实现本地输出功能。
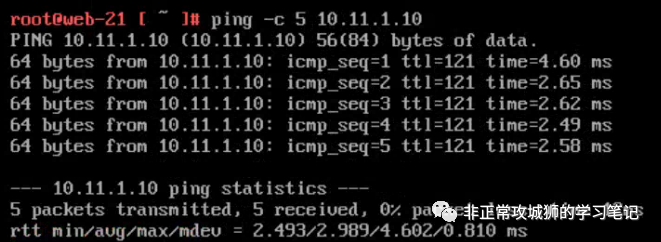
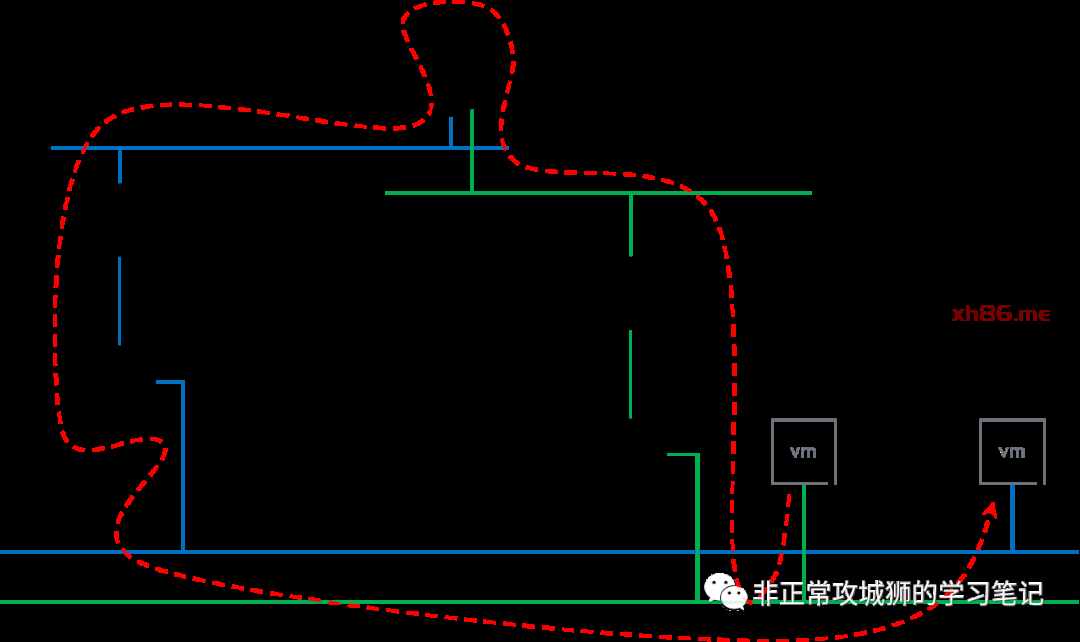
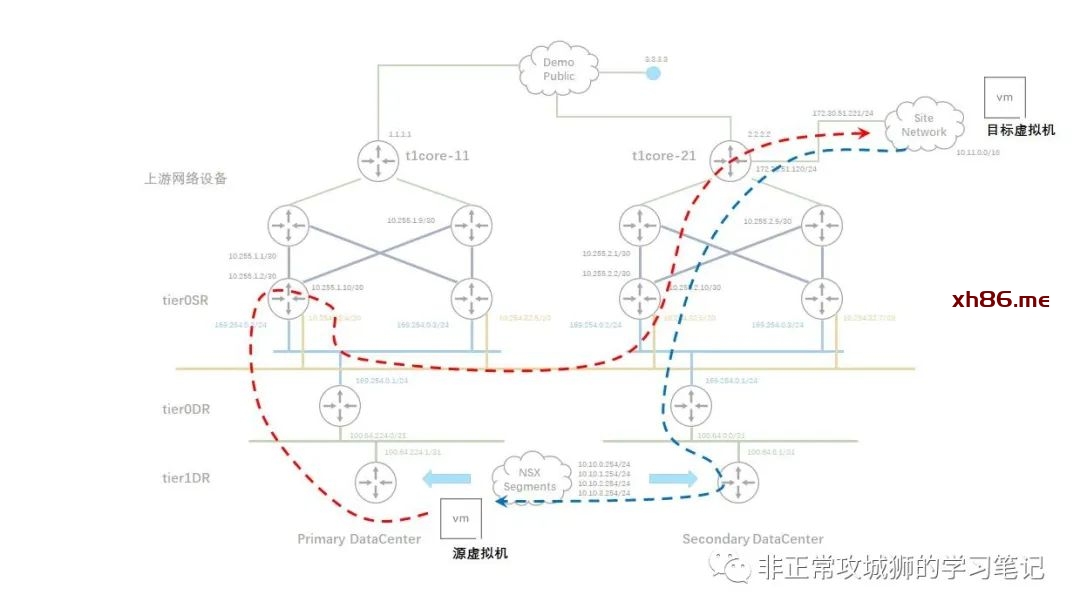
真正承载这个“必要的跨数据中心流量”转发的就是跨数据中心的Inter-SR链路;也就是之前我们通过“get logical-switches”命令看到的其中一个延伸Global Segment。结合TraceRoute的输出结果,我们可以将整个数据包路由和转发的路径大致上描绘出来:
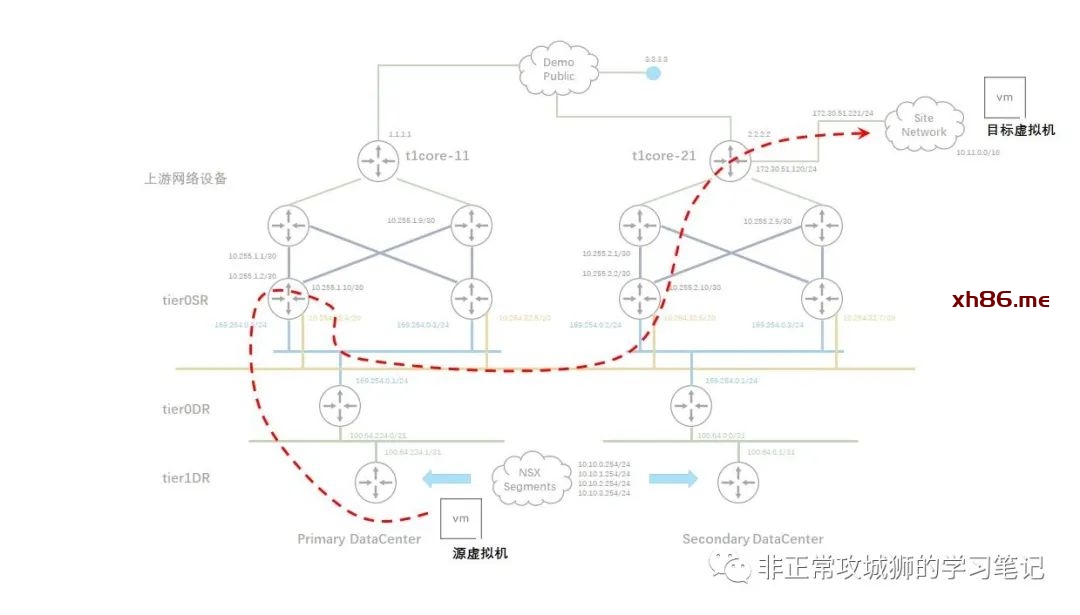
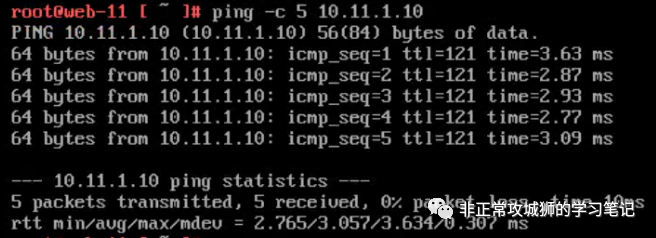
如上图所示,在前往目的地的旅程中,只有Inter-SR之间的流量会通过RTEP封装并经过跨数据中心Underlay链路进行转发。那“回程的数据包”也是如此么?这需要在目的虚拟机10.11.1.10上同样使用TraceRoute命令来验证。如果各位看官看过之前笔者其他NSX相关的分享,应该可以猜的到“回程数据包走向一定是不一样的路径”,这是NSX网络“先路由后转发”的又一个经典用例呈现。
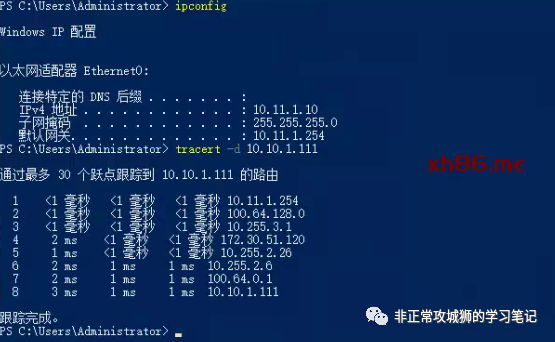
TraceRoute命令的结果验证了我们的猜想,如下图所示:
从目标虚拟机的回包会在Secondary数据中心经过Tier0SR入口进入到NSX内联网络,再逐级转发到位于Secondary DataCenter的Tier1DR下联的10.10.1.0/24分段后,再经过RTEP封装和跨数据中心链路转发到目标虚拟机10.10.1.111。
因此,关于此类“异地内部访问”可行性得到了一个肯定的答案。结合6.5和6.6的分析可以归纳得出2个结论:
1. 在Tier1SR存在的场景下,需要在上游物理网络设备添加静态路由后才能实现异地内部网络互访;
2. 在除了Tier0SR之外,没有其他Tier1SR存在的场景下,无论是一层网络还是二层网络拓扑,Federation原生就能实现内部网络异地互访。
一层架构的NSX网络拓扑不利于有状态服务的启用和ECMP功能的实现,笔者个人并不提倡采用这种架构。
是否有Tier1SR会对本地输出和内部网络异地互访的实现产生影响;如果不需要部署有状态的服务(如LB、NAT等),笔者推荐不为延伸的Tier1网关分配Edge集群,从而更好地实现本地输出功能。
最后很重要的一点:
是否启用Tier1SR是针对实际的项目需求来决定的。Requirement、Assumption、Constraint、Risk共同决定了Tier1SR是否有必要部署。诸如一些多租户的环境中,网络地址重叠情况普遍存在的场景,就必须要通过SNAT和Load Balancer来实现南北向互访,此时就要考虑启用Tier1SR的必要性。对此,就笔者个人的项目设计思路来说,会考虑“混合型架构”:
A. 采用二层架构,提供更好地南北向链路带宽和更灵活地网络拓扑;
B. 至少建立两种不同类型的延伸Tier1网关,一种是无SR实例的,一种是有SR实例的。
C. 根据实际的业务需求,将分段连接到不同类型的Tier1网关。充分利用NSX网络的可塑性、灵活性和安全性,结合“本地输出”的实现,从而更好地为企业业务助力。